Debian
- Installation et configuration de SAMBA
- Base de Bash
- Procédure Apache: PMA et BDD à distance
- Installation d'un serveur web Debian9 - PHP 7.1 - MariaDB - Apache2 - CMS Joomla
- Commande MAN
- Commande Info
- Commande AT
- Système de fichiers
- Processus
- Cron
- Commande Sed
- Commande Awk
- DHCP sur Debian
- Installation de Nextcloud
- Installation de GLPI
- Serveur Asterisk
- Failover avec Hearbeat, rsync et réplication mysql
- Migration d'un serveur GLPI
- Préparation du nouveau système
- Sauvegarde de l'ancien GLPI
- Restauration des données de la base MySQL
- Installation de GLPI
- Installation automatisé de Debian 10
- Mise à jours automatique
- Commandes de base
- Installation de Discord sur Debian 11
- SSH - Ajout de la 2FA
- Réseau
Installation et configuration de SAMBA
Samba, ça se danse ?
Hum, pas vraiment.
Samba permet de partager des ressources entre machines basés sur Unix et des machines windows.
C'est une suite logicielle implémentant le protocole SMB (Server Message Block) sur les systèmes unix.
Samba implémente le côté serveur de ce protocole et permet ainsi de partager des ressources (répertoires, imprimantes, etc.) vers des clients réseaux Windows, Linux, Mac... Il implémente également la partie cliente de SMB, offrant ainsi la possibilité aux systèmes Unix d'accéder aux ressources partagées par des systèmes d'exploitation Microsoft.
Installation de Samba
Après avoir fait les mise à jour du Debian, installons Samba avec les commandes suivantes:
apt-get install samba
Configuration de Samba
Une fois samba installé, nous pouvons le configurer. Pour cela, il faut aller dans le dossier suivant:
cd /etc/samba
On fait une copie du fichier pour pouvoir remettre la configuration par défaut en cas d’erreur:
cp smb.conf smb.conf.save
Nous pouvons maintenant ouvrir le fichier de configuration:
nano smb.conf
Dans le fichier de configuration, nous allons modifier les lignes suivantes:
- interfaces 10.0.0.0/8 (À remplacer par le reseau de votre choix)
- browseable = yes
On crée ensuite le répertoire:

Pour que l’utilisateur root ai accès au samba, il faut le rajouter dans la base d’utilisateur de samba. Pour cela il faut faire la commande suivante:
smbpasswd -a root
La console va vous demander de taper le mot de passe de l’utilisateur. Tapez le deux fois et votre utilisateur à ses accès !
Dans l’explorateur windows, tapez l’ip de votre serveur debian. Pour ma part:
\\10.10.1.4
 On voit bien le dossier utilisateur ( Dans mon cas, root) et le dossier de mon site précédemment crééDans la fenêtre qui s’ouvre, entrer l’utilisateur et le mot de passe précédemment créé dans le samba
On voit bien le dossier utilisateur ( Dans mon cas, root) et le dossier de mon site précédemment crééDans la fenêtre qui s’ouvre, entrer l’utilisateur et le mot de passe précédemment créé dans le samba
Et voilà, j’ai accès au fichier de mon site !

Base de Bash
Shell
Sous Linux, un shell est l’interpréteur de commandes qui fait office d’interface entre l'utilisateur et le système d’exploitation. Il s’agit d’interpréteurs, cela implique que chaque commande saisie par l’utilisateur et vérifiée puis exécutée. Nous avons déjà parlé des différents types de shell existants (csh, tcsh, sh, bash, ksh, dash, etc.). Nous travaillerons plus avec le bash (Bourne Again SHell).
Pour rappel, un shell possède deux principaux aspects :
- Un aspect environnement de travail
- Un aspect langage de programmation
L’environnement
L’environnement de travail d’un shell doit être agréable et puissant (rappel CLI GUI), bash permet entre autres choses de :
- Rappeler des commandes précédentes (historique)
- Modifier en ligne du texte de la commande courante (bi, emacs, nano)
- Gestion des travaux lancés en arrières-plan (jobs)
- Initialisation adéquate des variables de configuration (chaîne d’appel de l’interpréteur, chemins de recherche par défaut)
Pour illustrer ça, voyons que le shell permet d’exécuter une commande en mode interactif ou bien par l’intermédiaire de fichiers de commandes (scripts). En mode interactif, bash affiche à l’écran une chaîne d’appel (appelée prompt ou invite) qui se termine par défaut par le caractère # pour l’administrateur (root), et par le caractère $ pour les autres utilisateurs. Sous windows le prompt est souvent le nom du chemin où l’on se trouve, suivis de > , par exemple : “C:\Windows\System32>”
Un langage de programmation
Les shells ne sont pas uniquement des interpréteurs de commandes mais de véritables langages de programmation, un shell comme le bash intègre :
- les notions de variables
- les opérateurs arithmétiques
- les structures de contrôle
- les fonctions
- etc.
Par exemple :
$ mavariable=5 #=> affectation de la valeur 5 dans la variable qui a pour nom “mavariable”
$ echo $((mavariable +3)) #=> affiche la valeur de l’expression mavariable
8Avantages et inconvénients des shells
L’étude d’un shell comme le bash dispose de plusieurs avantages :
- langage interprété, il est facile de trouver les erreurs et de les traiter
- modification rapide sans besoin de recompiler
- langage orienté chaîne de caractères (pas de pointeurs), moins de risque d’avoir des erreurs d’adressage.
- prototypage rapide d’application, il est facile de composer des programmes avec les commandes existantes et l’utilisation des tubes et substitution dans l’environnement Unix
- langage “glu”: on peut connecter des composants écrits dans des langages différents. Ils doivent juste respecter certains standards :
- lire sur l’entrée standard
- accepter des arguments et options éventuels,
- écrire ses résultats sur la sortie standard
- écrire les messages d’erreurs sur la sortie dédiée au erreur.
Voyons maintenant certains inconvénients des shells :
- La syntaxe est “ésotérique” et d’accès difficile pour les débutants
- Suivant le contexte, l’ajout ou l’oubli d’un espace peut provoquer des erreurs de syntaxe ou de traitement
- Plusieurs syntaxes pour implanter la même fonctionnalité (principalement à cause de la compatibilité ascendante avec le Bourne Shell
- Le sens de certains caractères spéciaux, comme les parenthèses, change avec le contexte, elle peuvent définir :
- une liste de commandes
- une définition de fonction
- imposer un ordre d’évaluation
- une expression arithmétique
Si vous voulez connaître le shell qui tourne actuellement, utilisez la commande ps, et si vous voulez connaître la version du bash :bash -- version
Variables
Ils existent différents types de variables utilisables dans le shell. Elles sont identifiées par un nom (suite de lettres, chiffres, caractères espace
ou souligné ne commençant pas par un chiffre. la casse est gérée). On peut classer 3 groupes de variables :
- utilisateurs (ex: a, valeur)
- prédéfinies par le shell (ex; PS1, PATH, REPLY, IFS, HOME)
- prédéfinies pour les commandes unix (ex: TERM)
Pour affecter une variable, on peut utiliser l’opérateur = ou bien la commande interne read (pour demander une saisie utilisateur)
Les variables locales :
Elles ne sont disponibles que dans l’instance du shell dans lesquelles elles ont été créées. (Elles ne sont pas utilisées par les commandes dans ce shell). Par défaut une variable est créée en tant que variable locale, on utilise couramment des lettres minuscules pour nommer ses variables locales.
Exemple : mavariablelocale = 1
Les constantes :
Une constante est une variable en lecture seul d’une certaine manière, elle n’a pas pour but d’être modifié dans le programme (d’où son nom). Pour créer une constante, vous pouvez utiliser la commande declare -r.
Exemple: declare -r pi=3.14159
Les variables d’environnement :
Les variables d’environnement existent dans le shell pour lequel elles sont créées, mais aussi pour toutes les commandes qui sont utilisées dans ce shell. On utilise couramment des majuscules pour nommer ses variables d’environnement.
Exemple1 :
#Transformer une variable
ENVVAR=10 #Création d’une variable locale
export ENVVAR #Transforme la variable locale en variable d’environnementExemple 2:
# Créer une variable d’environnement
export ENVVAR2 = 11 # Première solution
declare -x ENVVAR3 = 12 # Deuxième solution
typeset -x ENVVAR4 = 13 # Troisième solutionCommandes utiles pour les variables :
- echo : Vous pouvez utiliser la commande echo si vous souhaitez connaître le contenu d’une variable.
Exemple : echo $PATH permettra d’afficher le contenu de la variable d’environnement PATH qui contient les chemins de fichier de
commande dans le shell.
$ set param1 param2
$ echo $1
param1
$ set --
$ echo $1
$ #on a perdu les valeursPour connaître le nombre de variables de position, il existe une variable spéciale $#
- shift : permet de décaler les variables de position (sans toucher au $0)
$ set a b c d e f g h i j # param 1 2 3 4 5 6 7 8 9
$ echo $1 $2 $#
a b 9
$ shift 2 # variable deviennent c d e f g h i j
$ echo $1 $2 $#
c d 7L’utilisation du shift sans argument équivaut à faire un shift 1
- unset : permet de supprimer une variable
$ set myvar=1
$ echo $myvar
1
$ unset myvar
$ echo $myvar
$Mon premier bash
#!/bin/bash
echo “Nom du programme : $0”
echo “Nombre d’arguments : $#”
echo “Source : $1”
echo “Destination $2”
cp $1 $2$ chmod u+x monpremierbash.sh
$
$ monpremierbash.sh /etc/passwd /root/copiepasswd
Nom du programme : ./monpremierbash.sh
Nb d’arguments : 2
Source : /etc/passwd
Destination : /root/copiepasswd
$$ set un deux trois quatre
$
$ echo $* # affiche tous les arguments
un deux trois quatre
$ echo $@ # affiche tous les arguments
un deux trois quatre
$ set un “deux trois” quatre # testons avec 3 paramètres et des guillemets
$ set “$*” # équivalent à set “un deux trois quatre”
$ echo $#
1
$ echo $1
un deux trois quatre
$ set un “deux trois” quatre # testons $@ avec 3 paramètres et des guillemets
$ set “$@” # équivalent à set “bonjour” “deux trois” “quatre”
$ echo $#
3
$ echo $2
deux troisSi dans un bash on souhaite supprimer les ambiguïtés d’interprétation des paramètres de position, on utilise le ${paramètre}, comme dans l’exemple suivant.
Exemple :
$ x=bon
$ x1=jour
$ echo $x1
jour
$ echo ${x}1
bon1
$ set un deux trois quatre cinq six sept huit neuf dix onze douze
$ echo $11
un1
$ echo ${11}
onzeIndirections
Bash offre la possibilité d’obtenir la valeur d’une variable v1 dont le nom est contenu “v1” dans une autre variable mavar. Il suffit pour cela d’utiliser la syntaxe de substitution : ${!mavar}.
Exemple :
$ var=v1
$ v1=un
$
$ echo ${!var}
un
$Ce mécanisme, appelé indirection,permet d’accéder de manière indirecte et par conséquent de façon plus souple, à la valeur d’un
deuxième objet. Voyons un autre exemple d’utilisation :
Exemple d’un fichier indir:
#!/bin/bash
agePierre=10
ageJean=20
read -p “Quel âge (Pierre ou Jean) voulez-vous connaître ? “ prenom
rep=age$prenom #construction du nom de la variable
echo ${!rep}
$ indir
Quel âge (Pierre ou Jean) voulez-vous connaître ? Pierre
10
$ indir
Quel âge (Pierre ou Jean) voulez-vous connaître ? Jean
20
$Ce mécanisme s’applique également aux deux autres types de paramètres : les paramètres de position et les paramètres spéciaux ($1, $2, , ...)
Résultats, Code de retour et opérateur sur les code de retour
Il ne faut pas confondre le résultat d’une commande et son code de retour : le résultat correspond à ce qui est écrit sur sa sortie standard; le code de retour indique uniquement si l’exécution de la commande s’est bien effectuée ou non. Parfois, on est intéressé uniquement par le code de retour d’une commande et non par les résultats qu’elle produit sur la sortie standard ou la sortie d’erreur.
Exemple :
$ grep toto pass > /dev/null 2>&1 #=> ou bien : grep toto pass &>/dev/null
$
$ echo $?
1 #=> on en déduit que la chaîne toto n’est pas présente dans passLes opérateurs && et || autorisent l’exécution conditionnelle d’une commande cmd suivant la valeur qu’a pris le code de retour de la dernière commande précédemment exécutée.
Exemple pour && :
$ grep toto pass > /dev/null 2>&1 #=> ou bien : grep toto pass &>/dev/null
$
$ echo $?
1 #=> on en déduit que la chaîne toto n’est pas présente dans passLa chaîne de caractères daemon est présente dans le fichier pass, le code de retour renvoyé par l’exécution de grep est 0; par conséquent, la commande echo est exécutée.
Exemple pour || :
$ ls pass tutu
ls : impossible d’accéder à tutu: Aucun fichier ou dossier de ce type pass
$ rm tutu || echo tutu non effacé
rm : impossible de supprimer tutu: Aucun fichier ou dossier de ce type
tutu non effacé
$Le fichier tutu n’existant pas, la commande rm tutu affiche un message d’erreur et produit un code de retour différent de 0; la commande interne echo est exécutée.
Exemple combiné || et || :
$ ls pass || ls tutu || echo fin aussi
pass
$Le code de retour ls pass est égal à 0 car pass existe, la commande ls tutu ne sera pas exécutée. D’autre part le code de retour de l’ensemble ls pass || ls tutu est le code de retour de la dernière commande exécutée, c’est-à-dire 0 (ls pass). donc echo fini aussi n’est pas exécutée.
Exemple combiné && et || :
$ ls pass || ls tutu || echo suite et && echo fin
pass
fin
$la commande ls pass a un code de retour égal à 0, donc la commande ls tutu ne sera pas exécutée; le code de retour de l’ensemble ls pass || ls tutu sera donc égal à 0. la commande echo suite et n’est pas exécutée donc le code de retour de l’ensemble reste 0 echo fin sera donc exécutée.
Boucles et structure de contrôle
case, structure de choix multiple
Syntaxe :
case mot in
[modele [ | modele] ...) suite de commandes ;; ] ...
esacLe shell va étudier la valeur de mot puis la comparer séquentiellement à chaque modèle. Quand un modèle correspond à mot, la suite de commandes associée est exécutée, terminant l’exécution de la commande interne case. Les mots case et esac sont des mots-clés; ils doivent être le premier mot d’une commande. suite de commandes doit se terminer par 2 caractères ; collés de manière à ce qu’il n’y ait pas d’ambiguïté avec l’enchaînement séquentiel de commande cmd1; cmd2; etc. Quand au modèle , il peut-être construit à l’aide de caractères et expressions génériques de bash (*, . , [], etc.). Dans ce contexte le symbole | signifiera OU. Pour indiquer le cas par défaut (si aucun des autres ne survient) on utilisera le modèle *. il doit être placé en dernier modèle. Le code de retour de la commande composée case est égal à 0, si aucun modèle n’a pu correspondre à la valeur de mot. Sinon, c’est celui de la dernière commande exécutée de suite de commandes.
Exemple 1: Programme shell oui affichant OUI si l’utilisateur a saisi le caractère o ou O
#!/bin/bash
read -p “Entrez votre réponse : “ rep
case $rep in
o|O ) echo OUI ;;
* ) echo Indefini
esacExemple 2 : Programme shell nombre prenant une chaîne de caractères en argument, et qui affiche cette chaîne si elle est constituée d’une suite de chiffres. ([:digit:] , [:upper:], [:lower:], [:alnum:]
#!/bin/bash
# on autorise l’utilisation des expressions générique
shopt -s extglob
case $1 in
+([[:digit:]]) ) echo ′′$1 est une suite de chiffres′′ ;;
esacExemple 3 : Si l’on souhaite ignorer la casse on peut modifier le flash de shopt
#!/bin/bash
read -p “Entrez un mot : “ mot
shopt -s nocasematch
case $mot in
oui ) echo ′′Vous avez écrit oui” ;;
* ) echo “$mot n’est pas le mot oui” ;;
esacWhile
La commande interne while correspond à l’itération ‘faire - tant que’ présente dans de nombreux langage de programmation.
Syntaxe :
while suite_cmd1
do
suite_cmd2
doneLa suite de commandes suite_cmd1 est exécutée, si son code de retour est égal à 0, alors la suite de commande suite_cmd2 est exécutée, puis suite_cmd1 est re-exécutée. Si son code de retour est différent de 0, la suite se termine. L’originalité de cette méthode est que le test ne porte pas sur une condition booléenne, mais sur le code de retour issu de l’exécution d’une suite de commandes. Une commande while, comme toutes commandes internes, peut être écrite directement sur la ligne de commande.
Exemple :
$ while who | grep root> /dev/null
> do
> echo “Utilisateur root est connecté”
> sleep 5
> done
Utilisateur root est connecté
Utilisateur root est connecté
Utilisateur root est connecté
^C
$Commande interne while est :
La commande interne : associée à une itération while compose rapidement un serveur (démon) rudimentaire.
Exemple :
$ while : #=> Boucle infinie
> do
> who | cut -d’ ‘-f1 > fic #=> Traitement à effectuer
> sleep 300 #=> Temporiser
> done &
[1] 1123 #=> pour arrêter l’exécution kill -15 1123
$On peut parfois utilisée la commande while pour lire un fichier texte. La lecture se fait alors ligne par ligne. Pour cela, il suffit de :
- placer la commande read dans suite_cmd1
- de placer les commandes de traitement de la ligne courante dans suite_cmd2
- de rediriger l’entrée standard de la commande while avec le fichier lire
Syntaxe :
while read [var1 ...]
do
Commandes de traitements
done < fichier à lireExemple :
#!/bin/bash
who > tmp
while read nom divers
do
echo $nom
done < tmp
rm tmpNotez que l’utilisation du while pour lire un fichier n’est pas très performante. On préférera en général utiliser une suite de filtre pour obtenir les résultats voulus (cut, awk, ...)
Modificateur de chaîne
Échappement
Différents caractères particuliers servent en shell pour effectuer ses propres traitements ($ pour la substitution, > pour la redirection, * en joker). Pour utiliser ces caractères particuliers en tant que simple caractère, il faut les échapper en les précédant du caractère \
Exemple :
$ ls
tata toto
$ echo *
tata toto
$ echo \*
*
$ echo \\
\
$Autre particularité, le caractère \ peut aussi échapper les retours à la ligne. On peut donc aller à la ligne sans exécuter la commande.
Comme nous l’avons déjà vu, les caractères “ et ‘ permettre une protection partielle, ou total (‘) d’une chaîne de caractères.
Exemple :
$ echo “< * $PWD ‘ >”
< * /root ‘ >
$
$ echo “\”$PS2\””
“> “
$ echo ‘< * $PWD “ >’
< * $PWD “ >’
$ echo c’est lundi
>
> ‘
cest lundi
$ echo c\’est lundi
c’est lundi
$ echo “c’est lundi”
c’est lundiChaîne de caractères longueur
Syntaxe : ${#paramètre}
Cette syntaxe permet d’obtenir la longueur d’une chaîne de caractères.
Exemple :
$ echo $PWD
/root
$ echo ${#PWD}
5
$ set “Bonjour à tous”
$ echo ${#1}
14
$ ls > /dev/null
$
$ echo ${#?}
1 #=> la longueur du code de retour (0) est de 1 caractèreChaîne de caractères modificateur
On peut modifier les chaîne de caractères directement :
Syntaxe : ${paramètre#modèle} pour supprimer la plus courte sous-chaîne à gauche
Exemple :
$ echo $PWD
/home/christophe
$ echo ${PWD#*/}
home/christophe #=> le premier caractère / a été supprimé
$
$ set “25b75b”
$
$ echo ${1#*b}
75b #=> Suppression de la sous-chaîne 25bSyntaxe: ${paramètre##modèle} pour supprimer la plus longue sous-chaîne à gauche
Exemple :
$ echo $PWD
/home/christophe
$ echo ${PWD##*/}
christophe #=> suppression jusqu’au dernier caractère /
$
$ set “25b75b”
$
$ echo ${1##*b}
bPour la suppression par la droite, c’est la même chose en utilise le caractère % comme contrôle
Syntaxe :${paramètre%modèle} pour supprimer la plus courte sous-chaîne à droite${paramètre%%modèle} pour supprimer la plus longue sous-chaîne à droite
On peut extraire une sous-chaîne également :
Syntaxe:${paramètre:ind} : extrait la valeur de paramètre de la sous-chaîne débutant à l’indice ind.${paramètre:ind:nb} : extrait nb caractères à partir de l’indice ind
Exemple :
$ lettres=”abcdefghijklmnopqrstuvwxyz”
$
$ echo {$lettre:20}
uvwxyz
$ echo {$lettre:3:4}
defg
$Remplacement dans une sous-chaîne
Syntaxe:${paramètre/mod/ch}
bash recherchera dans paramètre la plus longue sous-chaîne satisfaisant le modèle mod puis remplacera cette sous-chaîne par
la chaîne ch. Seule la première sous-chaîne trouvée sera remplacée. mod peut être des caractères ou expressions génériques.${paramètre//mod/ch} :
Pour replacer toutes les occurrences et pas seulement la première${paramètre/mod/} :${paramètre//mod/} :
Supprime au lieu de remplacer
Exemple :
$ v=totito
$ echo {$v/to/lo}
lotito
$ echo {$v//to/lo}
lotiloStructure de contrôle for et if
Itération et for
Syntaxe 1:
for var
do
suite_de_commandes
done
Syntaxe 2:
for var in liste_mots
do
suite_de_commandes
doneDans la première forme, la variable var prend successivement la valeur de chaque paramètre de position initialisé
Exemple :
$ cat for_args.sh
#!/bin/bash
for i
do
echo $i
echo “next ...”
done
$ ./for_args.sh first second third
first
next ...
second
next ...
third
next ...Exemple 2:
$ cat for_set.sh
#!/bin/bash
set $(date)
for i
do
echo $i
done
$ ./for_set.sh
samedi
29
Juin
2019,
12:09:21
(UTC+0200)
$La deuxième syntaxe permet à var de prendre successivement la valeur de chaque mot de liste_mots.
Exemple :
$ cat for_liste.sh
#!/bin/bash
for a in toto tata
do
echo $a
doneSi liste_mots contient des substitutions, elles sont préalablement traitées par bash
Exemple 2:
$ cat affiche_ls.sh
#!/bin/bash
for i in /tmp ${pwd}
do
echo “ --- $i ---”
ls $i
done
$ ./affiche_ls.sh
--- /tmp ---
toto tutu
--- /home/christophe
for_liste.sh affiche_ls.sh alpha tmpIf et le choix
La commande interne if implante le choix alternatif
Syntaxe :
if suite_commande1
then
suite_commande2
[elif suite_de_commandes; then suite_de_commande] ...
[else suite_de_commandes]
fiLe principe de fonctionnement est le même que pour le for, on test la valeur de retour d’une commande plutôt qu’une valeur booléenne simple. Donc dans notre exemple, suite_commande2 est exécuté, si suite_commande1 renvoi 0 (pas d’erreur). Sinon c’est elif ou bien else qui sera exécuté.
Exemple :
$ cat rm1.sh
#!/bin/bash
if rm “$1” 2> /dev/null
then echo $1 a été supprimé
else echo $1 n\’a pas été supprimé
fi
$ >toto
$ rm1 toto
toto a été supprimé
$
$ rm1 toto
toto n’a pas été supprimé
$Lorsque rm1 toto est lancé, si le fichier toto est effaçable, il le sera, et la commande rm renvoi 0.
Notez qu’il est possible d’imbriquer les if ensembles
Exemple :
if...
then....
if...
then ...
fi
else ...
fiTests
Dans les bash, vous retrouverez souvent une notation de commande interne [[ souvent utilisé avec le if. Elle permet l’évaluation de d’expressions conditionnelles portant sur des objets aussi différents que les permissions sur une entrée, la valeur d’une chaîne de caractères ou encore l’état d’une option de la commande interne set.
Syntaxe: [[ expr_conditionelle ]]
Les deux caractères crochets doivent être collés et un caractère séparateur doit être présent de part et d’autre de expr_conditionelle. Les mots [[ et ]] sont des mots-clés. On a vu que le if fonctionne selon la valeur de retour d’une commande, et pas d’un booléen, cette syntaxe permet “d'exécuter un test” qui renverra 1 si le test est vrai, 0 sinon. Si l’expression contient des erreurs syntaxique une autre valeur sera retournée. La commande interne [[ offre de nombreuses expressions conditionnelles, c’est pourquoi seules les principales formes de exp_conditionnelle seront présentées, regroupées par catégories.
Permission
-r entrée vraie si entrée existe et est accessible en lecture par le processus courant
-w entrée vraie si entrée existe et est accessible en écriture par le processus courant
-x entrée vraie si entrée existe et est accessible en exécutable par le processus courant ou si le répertoire entrée existe et
le processus courant possède la permission de passage
Exemple :
$ echo coucou > toto
$ chmod 200 toto
$ ls -l toto
--w- --- --- 1 christophe christophe 29 juin 1 14:04 toto
$
$ if [[ -r toto ]]
> then cat toto
> fi
$ => rien ne ce passe
$ echo $?
0 => code de retour de la commande interne if
$
MAIS
$ [[ -r toto ]]
$ echo $?
1 => code de retour de la commande interne [[
$Type d’une entrée
-f entrée vraie si entrée existe et est un fichier ordinaire
-d entrée vraie si entrée existe et est un répertoire
Exemple :
$ cat afficher.sh
#!/bin/bash
if [[ -f “$1” ]]
then
echo “$1” : fichier ordinaire
cat “$1”
elif [[ -d “$1” ]]
then
echo “$1” : répertoire
ls “$1”
else
echo “$1” : type non traité
fi
$ ./afficher
. : répertoire
afficher.sh test.sh toto alpha rm1.sh
$Renseignement divers sur une entrée
-a entrée vraie si entrée existe
-s entrée vraie si entrée existe et sa taille est différente de 0 (un répertoire vide > 0)
entrée 1 -nt entrée 2 vraie si entrée 1 existe et sa date de modification est plus récente que celle de entrée2
entrée1 -ot entrée 2 vraie si entrée1 existe et sa date de modification est plus ancienne que celle de entrée2
Exemple :
$ > err
$
$ ls -l err
-rw-rw-r-- 1 christophe christophe 0 juin 29 14:30 err
$ if [[ -a err ]]
> then echo err existe
> fi
err existe
$ if [[ -s err ]]
> then echo err n’est pas vide
> else err est vide
> fi
err est vide
$Longueur d’une chaîne de caractère
-Z ch vraie si la longueur de ch est égale à 0
ch ou (-n ch) vraie si la longueur de ch est différente de 0
ch1 < ch2 vraie si ch1 précède ch2
ch1 > ch2 vraie si ch1 suit ch2
ch == mod vraie si la chaîne ch correspond au modèle mod
ch != mod vraie si la chaîne ch ne correspond pas au modèle mod
-o opt vraie si l’option interne opt est sur on
Important : il existe un opérateur =~ qui permet de mettre en correspondance une chaîne de caractères ch avec une expression
régulière.
Exemple :
$a=01/01/2010
$[[ $a =~ [0-9]{2}\/[0-9]{2}\/[0-9]{2,4} ]]
$ echo $?
0
$ a=45/54/1
$[[ $a =~ [0-9]{2}\/[0-9]{2}\/[0-9]{2,4} ]]
$ echo $?
1Expressions conditionnelles
( cond ) vraie si cond est vraie
! cond vraie si cond est fausse
cond1 && cond 2 vraie si cond1 et 2 sont vraie, l’évaluation s’arrête si cond1 est fausse
cond1 || cond2 vraie si cond1 ou 2 sont vraie.
Exemple :
$ ls -l /etc/at.deny
-rw-r----- 1 root daemon 144 oct. 25 2018 /etc/at.deny
$
$ if [[ ! ( -w /etc/at.deny || -r /etc/at.deny ) ]]
> then
> echo OUI
> else
> echo NON
> fi
OUI
Procédure Apache: PMA et BDD à distance
Pour les besoin de mon site, je devais séparer la base de donnée des fichiers de mon site. Voici donc un tuto qui explique comment faire.
DEB1: Debian avec apache, PhpMyAdmin
DEB2: Debian avec My SQL
Installation de DEB1
Après avoir installé le debian et avoir fait les mises à jour, vous pouvez installer Apache2
apt-get install apache2
Une fois l’installation faite on vérifie si apache à bien mis en place le site par défaut. Pour cela on récupère l’IP de la VM avec la commande
ip a

On n’a plus qu’à rentrer l’IP dans un navigateur et voila!

Nous avons bien la page par défaut d’Apache, ce qui signifie que notre serveur Web est en place !
Nous pouvons donc maintenant installer PhpMyAdmin, qui est une interface de gestion de base de données simplifié. Pour cela:
apt-get install phpmyadmin



Ici nous avons une erreur, ce qui est parfaitement normal puisqu’il n’y a pas de base de données sur ce serveur. On choisi ignorer, et l’installation va se finir

Pour des raisons de simplicité on va déplacer l’interface phpmyadmin directement dans le dossier www. Pour cela:

Installation de DEB2
Une fois l’installation de Debian et les mises à jours faites, installer MySQL à l’aide de la commande suivante
apt-get install mysql-server
Une fois l’installation faite, on vérifie son fonctionnement avec la commande
mysql
On arrive dans la console mysql,ce qui prouve le bon fonctionnement !

On va créer une base de données test:
mysql
create database bddsite character set utf8;
grant all privileges on *.* to root@’192.168.%.%’ identified by ‘root’
exit
Configuration de DEB1
Une fois la base de donnees en place, on va pouvoir la mettre dans la configuration de PhpMyAdmin: Pour cela, éditez le fichier de configuration suivant:
nano /etc/phpmyadmin/config.inc.php
Ajoutez les lignes suivantes en bas de la configuration

Enregistrez, et redémarrez apache
/etc/init.d/apache2 restart
Configuration de DEB2
Pour pouvoir autoriser la connexion à distance à la BDD, il faut éditer le fichier suivant
nano /etc/mysql/mariadb.conf.d/50-server.cnf
Et remplacer le bind-address par 0.0.0.0

Redémarrez mysql à l’aide de la commande:
/etc/init.d/mysql restart
Test connexion à la BDD
Une fois la configuration faite, on peux se connecter à PhpMyAdmin
http://ip/phpmyadmin
Dans choix du serveur, pensez à mettre le serveur distant

Et ça fonctionne !

Installation d'un serveur web Debian9 - PHP 7.1 - MariaDB - Apache2 - CMS Joomla
Voici un mémo pour faire un serveur web de base pour le CMS Joomla.
Note : Cette installation est juste pratique, il faudra ajouter vos certificats, configurer correctement Debian et Apache pour pas lâcher trop d'informations.
Attention, le VHOST est à configurer en fonction de vos besoins, celui-ci est volontairement "léger".
Installation
Récupérer l'iso Debian9 net-install et faire l'installation de base (ssh et fichiers de bases)
Récup des dépôts pour php 7.1 :
apt-get install apt-transport-https lsb-release ca-certificateswget -O /etc/apt/trusted.gpg.d/php.gpg https://packages.sury.org/php/apt.gpgecho "deb https://packages.sury.org/php/ $(lsb_release -sc) main" > /etc/apt/sources.list.d/php.listapt-get update
Installation PHP 7.1 et Apache 2apt install --no-install-recommends php7.1 libapache2-mod-php7.1 php7.1-mysql php7.1-curl php7.1-json php7.1-gd php7.1-mcrypt php7.1-msgpack php7.1-memcached php7.1-intl php7.1-sqlite3 php7.1-gmp php7.1-geoip php7.1-mbstring php7.1-redis php7.1-xml php7.1-zip php7.1-cli php7.1-common
apt install apache2 apache2-utils unzip
** On active php pour Apache et le mode rewrite (ré écriture au vol des URL) :a2dismod mpm_eventa2enmod php7.1a2enmod rewrite
** On vérifie le fonctionnement en mettant une page php dans /var/www/html/ , (le dossier html est le dossier par défaut d'Apache). ** J'utilise nano mais vous pouvez choisir votre éditeur.nano /var/www/html/test.php
** On met ce code à l'intérieur :
<?php
phpinfo();** On enregistre et on ferme l'éditeur nano (Ctrl+O et Ctrl+X)
systemctl restart apache2
Pour vérifier le fonctionnement et la version, sur le navigateur ip/test.php
** Lorsque c'est vérifié, pour éviter une faille de sécurité, il est plus prudent de supprimer le fichier.rm /var/www/html/test.php
**Passons à l'installation de la base de donnée :apt-get install mariadb-server mariadb-client
** Sécuriser MariaDB :mysql_secure_installation
** Comme demandé, tape le mot de passe root de Debian.
** Puis répondre "Y" (ou Entrée) à toutes les questions suivantes.
** Commence par donner un mot de passe à l'utilisateur root de MariaDB différent de l'utilisateur root de votre Debian.
** Cet utilisateur root de la base de données aura tous les droits d'accès, pour des raisons évidentes de sécurité, je vous recommande d'utiliser un mot de passe complexe !
** Maintenant, on met à jour de nouveau :apt update && apt upgrade
Installation terminé
Création des DOSSIERS
** Il faut charger les systèmes CMS (depuis un wget ou via WinSCP) et placer les fichiers dans les dossiers correspondants.cd /var/www/wget https://github.com/AFUJ/joomla-cms-fr/archive/master.zipunzip master.zipmv joomla-cms-fr-master test
(** pour renommer le dossier dézippé en test)
** Remise en place des droits, maintenant, on ré-attribue le propriétaire et le groupe www-data aux dossiers dans /var/www/ :cd /var/www/chown -R www-data: *
** Lorsque le site aura besoin "d'écrire", il faut lui permettre de le faire avec l'utilisateur / groupe www-data.
** Créer les VHosts (exemple pour Joomla!) - Ne pas oublier le port d'écoute !!
** !! Attention, Apache ne prend pas en compte les fichiers de configuration qui ne se termine pas par "**.conf" !!
** !! Attention : le VHOST est volontairement simple, à ne pas utiliser en dehors du réseau local
nano /etc/apache2/sites-available/biomediqa.conf
<VirtualHost *:80>
ServerAdmin contact@test.com
ServerName test
DocumentRoot /var/www/test/
</VirtualHost>** Mise en place du site pour Apachea2ensite test
** Une fois fait, il faut mettre à jour le serveur DNS pour lier l'IP et le vhost (si c'est en local, le fichier host de votre distribution fera l'affaire)
x.x.x.x test
Création de la Base de Données
** Mise en place de l'utilisateur et de la base de donnée pour test:mysql -u root -p
--CREATE DATABASE nom_db;
--GRANT ALL PRIVILEGES ON nom_db.* TO "user_db"@"localhost" IDENTIFIED BY 'mot_de_passe';
--FLUSH PRIVILEGES;
CREATE DATABASE test_db;GRANT ALL PRIVILEGES ON test_db.* TO "testuser"@"localhost" IDENTIFIED BY '123456789';FLUSH PRIVILEGES;exit
** Lorsque c'est fait pour chaque site, et vu que nous sommes au début, on peut reboot.
** Ensuite se connecter sur le nom de domaine (http://test)
Commandes utiles pour manager la base de données en ligne de commande
** Pour lister les tables de données :show databases;
** Supprimer une bddmysql> drop database exemple;
** Création d’un utilisateur
Première action, création d’un utilisateur avec un mot de passe. Deux façons de faire sont possibles en fonction de la façon dont vous voulez attribuer le mot de passe au moment de la création de l’utilisateur.
** Lister les utilisateurs select user,host from mysql.user;
- -- Mot de passe en clair dans la requête
CREATE USER 'user'@'localhost' IDENTIFIED BY 'password'; - -- Mot de passe passé sous un algorithme de Hash
SELECT PASSWORD('password');-- Création du Hash du mot de passeCREATE USER 'user'@'localhost' IDENTIFIED BY PASSWORD '*2470C0C06DEE42FD1618BB9900DFG1E6Y89F4';
** Renommer un utilisateurRENAME USER 'user'@'localhost' TO 'user2'@'localhost';
** Changer un mot de passeSET PASSWORD FOR 'user'@'localhost' = PASSWORD('newpassword');
** Attribution de privilègesGRANT SELECT, INSERT, UPDATE, DELETE ON `database`.* TO 'user'@'localhost';
** Si vous voulez attribuer tout les droits sur une base de données à un utilisateur, il vous suffit d’effectuer la requête suivante :GRANT ALL ON `database`.* TO 'user'@'localhost';FLUSH PRIVILEGES;
** Révocation de privilègesREVOKE ALL PRIVILEGES, GRANT OPTION FROM 'user'@'localhost';
** Voir les priviléges d'un utilisateur sur une baseshow grants for "utilisateur"@"localhost";
** Suppression UtilisateurDROP USER 'user'@'localhost';
Commande MAN
Si vous faites un man wc, vous obtenez la fenêtre suivante :

La commande man utilise un outil d’affichage de pages (less ou more, selon les
distributions)
Une page est un « manuel » d’une commande.
Grâce au « pageur » il est possible de naviguer dans la documentation.
Dans le man, vous pouvez tapez “h” pour obtenir l’aide d’utilisation de l’aide !

Sections
Les pages d’aides sont divisés en sections. Chaque page appartient également à une
section (type de manuel). 9 sections (type de manuelles) essentielles :
| Numéro | Type de manuel |
| 1 | Exécutable ou commande shell |
| 2 | Fonction du kernel (appel système) |
| 3 | Fonction dans une bibliothèque (appel bibliothèque) |
| 4 | Fichiers spéciaux (généralement dans le dossier /dev) |
| 5 | Formats de fichiers, jeu de caractères, certains paramètres du système |
| 6 | Jeux |
| 7 | Divers (macros par exemple) |
| 8 | Commandes d’administration du système |
| 9 | Routines du kernel |
prenons par exemple, “man cat”

Sections multiple
Il peut existe plusieurs sections de manuel pour un même mot clé.
Par exemple “passwd”:
- La commande passwd
- le fichier passwd (contient des informations de profil des utilisateurs)
-
Lors de l’utilisation du man passwd, la priorité est donné à la section avec le numéro le plus
faible :
- Exécutable, commande shell : section 1
- Profils utilisateurs: section 5
Si l’on veut une section spécifique, on peut utiliser : man 5 passwd
Si vous voulez savoir les sections qui existe pour un mot clé, la commande :
whatis est faites pour ça :

Ici, il existe les pages: 1 et 5, mais aussi 1SSL et 1ssl
la commande man -f fait la même chose

Autre fonction utile :
Je cherche les commandes qui pourraient m’aider à régler des problèmes de mots de
passe, mais je ne sais pas trop lesquelles existent....man -k

Commande Info
Man est une commande à utiliser pour obtenir « la » référence détaillée. C’est assez lourd et on ne sait pas trop comment « apprendre » facilement avec.
La commande info est recommandée pour « dégrossir » des sujets, les informations sont plus succinctes. Cette commande, à elle seule, remplace tout manuel papier, tout cours « de base » à « confirmé » sur Linux!!!
Info est organisé comme un « gros manuel » de tout le système et son contenu:
Pour une prise en main rapide:
Consulter le sommaire: saisir info
Chaque rubrique navigable débute par *
Naviguer entre * avec la touche tab
Afficher la rubrique avec la touche entrée
(on se retrouve bien souvent dans des sous rubrique)
Menu principal avec la touche d
L’argument --help
Il est courant de pouvoir obtenir de l’aide avec l’option –help d’une commande (double - )
Précis...concis

Commande AT
Elle est utilisée pour planifier des actions qui doivent se réaliser ultérieurement et une seule fois. (Une sorte de tache planifié mais sans la répétition).
Par défaut elle n’est pas forcément installé sur votre distribution, pour l’installer :apt-get install at
Si ca ne marche pas , faites avant un apt-get update.
Puis lancer le service avec :service atd start
- ou “systemctl start atd.service” puis systemctl enable atd.service
Exemple d’utilisation :at now +2 minutes
Au prompt, entrer la commande désirée, par exemple :at> echo “A noter” > /root/exercicesAT.txt
Pour sortir du prompt, faire un CTRL+D
Le système vous renverra un message de la forme :
Job 1 at JOUR MOI NUMJOUR HEURE ANNEE
Avec la commande atq, vous pouvez visualiser la file de traitement, le premier numéro est le numéro du job dans la file de traitement, suivi de l’horodatage, puis de l’utilisateur ayant lancé le job.
exemple 2 :at 4:00 AM tomorrowat> rm /root/exercicesAT.txtat> <EOT>
Pour supprimer un job at, il faut utiliser son numéro obtenu avec atq :atrm numjob
Grâce à l’option -f, suivi du script puis de l’heure on peut lancé directement un bash :
ex : at -f /root/test.sh 10:30 PM
Vous pouvez sécuriser la commande at, grâce au fichier /etc/at.allow pour placer dans ce
fichier les utilisateurs autorisés (whitelist)
Ex : nano /etc/at.allow
root
Seul root pourra utiliser la commande at.
Système de fichiers
Un système de fichiers est une façon d’organiser et de stocker une arborescence sur un support (disque, cd, ...). Chaque OS a sa propre organisation.
Linux possède son système appelé ext2 mais peut en gérer d’autres. La liste se trouve en général dans /proc/filesystems. L’utilisateur peut donc accéder sous Linux à d’autres systèmes de fichiers (DOS, Vfat, NTFS, ...) provenant d’un périphérique ou importé par le réseau.
Tout est fichier
Comme nous l’avons vu précédemment, dans le système linux, tout est considéré comme un fichier :
- Les fichiers
- Les dossiers
- Un disque dur
- La mémoire
- Un port USB aussi .
Mais parmi ces fichiers, tous n’ont pas la même catégorie. On peut en effet retrouver :
- fichiers normaux (texte, exécutables, ...); symbole “-”
- fichiers répertoires, ce sont des fichiers conteneurs qui contiennent des références à d’autres fichiers. Véritable charpente de
l’arborescence.; symbole “d”
- fichiers spéciaux, ils sont situés dans /dev, ce sont les points d’accès préparés par le système aux périphériques. Le montage va
réaliser une correspondance de ces fichiers spéciaux vers leur répertoire “point de montage”. Par exemple, le fichier /dev/hda permet l’accès et le chargement du 1er disque IDE.
- Accès caractère par caractère; symbole “c”
- Dispositif de communication ; symbole “p”
- Accès par bloc ; symbole “b”
- fichier lien symboliques, ce sont des fichiers qui ne contiennent qu’une référence (un pointeur) à un autre fichier. Cela permet d’utiliser un même fichier sous plusieurs noms sans avoir à le dupliquer sur le disque. ; symbole “l”
Le processus de montage que l’on évoque pour les fichiers spéciaux, avec sa commande mount est le moyen de faire correspondre les parties de l’arborescence et les partitions physiques de périphérique. Il permet de plus d’affecter tout système extérieur (cd, zip, réseau) à un répertoire créé pour cela dans l’arborescence. Il suffira ensuite de se déplacer à ce répertoire, appelé point de montage, qui est en fait un répertoire “d’accrochage”, pour accéder à ses fichiers (bien sûr, conformément aux permissions que possède l’utilisateur).
FHS (Filesystem hierarchy standard)
C’est la standardisation des noms et des emplacements des dossiers, et de leurs contenus.

Voici la structure qui est recommandée d’après les spécifications

SI l’on détaille :
- /bin : Les fichiers binaires les plus importants
- /boot : le Kernel et le bootloader
- /dev : les périphériques
- /etc : les fichiers de configurations spécifiques à l’ordinateur
- /home : Emplacement contenant les profils dossiers utilisateur
- /mnt : Emplacement d’accès aux systèmes de fichiers montés dans l’OS
- /lib : Bibliothèques de fonctions utilisées par les commandes /bin et /sbin
- /proc : Le kernel place ici l’état en temps réel du fonctionnement du système et des processus
- /root : Dossier du profil “root”
- /sbin : Contient des exécutables
- /tmp : à utiliser pour la création de fichiers temporaires
- /usr : Applications installées par les utilisateurs (et souvent les données qui vont avec) souvent un des plus lourds!
- /var/log : Fichiers logs
- /var/spool : File d’attente d’impression
- /var/tmp : Fichiers temporaires
Gob et Jokers
Le file globing, est l’opération qui transforme un caractère joker en une liste de chemins, et de fichiers correspondants qui formeront le résultat.
Le file globing est l’ancêtre des expressions régulières. Sous Bash, les jokers possibles sont :
- Le caractère *
- Le caractère ?
- Les caractères []
Le caractère * est utilisé pour obtenir la liste de tout le contenu
Ex : ls => ls *
Il est possible de préciser plus de caractéristiques :
ls D* => Tous les fichiers commençant par un D
ls d*v* => Tous les fichiers commençant par un d minuscule mais contenant aussi la lettre v
Le caractère ?, est utilisé pour préciser que le résultat doit contenir un seul ou plusieurs caractères (un par joker ?)
Exemple :
ls ? => liste tout ce qui ne contient qu’un seul caractère
ls ?? => liste tous les fichiers qui n’ont que 2 caractères
ls w?? => liste tous les fichiers qui ont 3 caractères et commençant par w
ls w??* => liste tous les fichiers qui commencent par w et contiennent au moins 3 caractères.
Le joker [], est utilisé pour spécifier une plage de caractères admissibles.
ls [a-f]?? => liste tous les fichiers dont la première lettre commence par a,b,c,d,e ou f et faisant 3 caractères.
ls [w]* => liste tous les fichiers commençant par w
ls [*] => ici l’étoile est son propre caractère, liste tous les fichiers commençant par *
ls *[0-9][0-9]* => liste tous les fichiers contenant 2 chiffres
ls [!a-y]* => ne liste que les fichiers commençant par autre chose que les lettres a à y. le ! inverse le résultat
ls *[^3-9] => liste tous les fichiers excluant ceux contenant les chiffres 3 à 9
Droit d’accès et permissions
Droits
Un fichier est caractérisé par un certain nombre de droits d’utilisation. Lorsque que l’on fait un ls -l, on remarque les éléments suivants :

le premiers bloc est définie comme suit :
_ Type de fichier (d, -, p, l, ...)
_ _ _ Droits du propriétaire du fichier (owner), dans l’ordre (lecture, écriture, exécution)
_ _ _ Droits du groupe auquel appartient le fichier (group), dans l’ordre (lecture, écriture, exécution)
_ _ _ Droits d’un utilisateur quelconque (user), dans l’ordre (lecture, écriture, exécution)
Pour rappel :
| Permission | Effet sur le fichier | Effet sur le dossier |
| r (read) | Autorise la lecture ou la copie du fichier et son contenu |
Sans droit d'exécution : autorisation de liste les fichiers dans le dossier |
| w (write) |
Autorise à supprimer ou modifier le contenu du fichier. Permet de supprimer le fichier |
Sur un dossier, il faut également l’attribut “execute” afin d’opérer des modifications |
| x (execute) |
Autorise un fichier d’être lancé comme un processus |
Autorise un utilisateur à entrer dans ce dossier |
L’attribut suivant (1 par exemple) est le nombre de lien symbolique vers ce fichier
Les 2 attributs d’après : root root définissent le propriétaire suivis par le groupe
L’utilisateur qui crée le fichier est considéré comme son propriétaire. Il faut savoir que seul root est habilité à modifier le propriétaire d’un fichier, avec la commande “chown”
Le groupe du fichier sera celui du groupe principal auquel appartient l’utilisateur qui crée ce fichier.
la commande “id” indique l’identité de l’utilisateur actuel, son group principal, et tous les groupes auxquels il appartient. Pour changer le groupe d’un fichier, on utilise la commande “chgrp” seuls root et le propriétaire du fichier peuvent changer le groupe d’un fichier.
Permissions
Seul root et le propriétaire du fichier disposent de la possibilité de modifier les permissions d’un fichier au moyen de la commande chmod
Exemples :
Ajouter les droits d’exécution au propriétaire du fichierchmod u+x monfichier
Supprimer les droits d’écriture pour le groupe :chmod g-w monfichier
Assigner des droits à plusieurs sections des attributs ;chmod o=r,g-w,u+x monfichier
Supprimer toutes les permissionschmod a=- monfichier
La méthode octale reste la plus rapide pour l’attribution, avec
r=4; w=2 et x=1
Pour donner les permissions rwx r-x r-x à un fichier, on va additionner les valeurs :
Owner: 4+2+1 => 7
Group : 4+1 => 5
Other : 4+1 => 5
=> chmod 755 monfichier
Attribut spéciaux -setuid
Cet attribut spécial permet d’appliquer à un fichier exécutable, d’autoriser d’autres utilisateurs à lancer l’exécutable, comme s’il étaient l’utilisateur root.chmod 4000
Exemple avec la commande passwd :
s -> permissions x+setuids (s)
S -> seule la permission setuid existe (pasx)

Attribut spéciaux -setgid
Même chose qu’avec setuid, mais pour le groupe utilisateurchmod 2000
- Appliqué à un fichier exécutable, afin de s’exécuter via le group du propriétaire, au lieu de celui de l'utilisateur qui lance l’exécutable
- Appliqué à un dossier, fait en sorte que le contenu créé dans ce dossier appartient au groupe qui possède le dossier (et pas celui de l’utilisateur qui crée le contenu dans ce dossier)
Attribut spéciaux -sticky
chmod 1000
L’utilité de cet attribut est d’empêcher d’autres utilisateurs de supprimer le contenu d’un autre utilisateur.
Pour supprimer un fichier, il faut les autorisations d’écriture sur le dossier parent. Ainsi, un admin crée un dossier accessible et modifiable par tous les utilisateurs. Tout le monde pourra supprimer le contenu de ce dossier ...
L’utilisation de cette permission sticky permet de définir pour un dossier que :
- L’utilisateur propriétaire d’un fichier, dans ce dossier, pourra supprimer le fichier
- root et l’utilisateur propriétaire du dossier parent pourra aussi
Héritage vs umask
Lorsque l’on crée un sous-dossier sous windows, ce dernier hérite des droits d’accès du dossier parent (par défaut). Il faut savoir que sous linux : NON ! ce n’est pas le cas! En effet le sous-dossier aura les droits créés selon la valeur umask de l’utilisateur créant le sous dossier.

Read vaut 4, write 2, execute 1, rien vaut 0.
Dans le cas de umask, ces valeurs précisent les permissions à supprimer des permissions “maximum” à la création !
Sur un fichier, les permissions maximales sont : rw- rw- rw- soit 666 en octal. La valeur umask de l’utilisateur créant le fichier va donc
permettre de supprimer certaines de ces valeurs! Cette valeur se code avec trois nombres de base en octale.
Ex, Si l’on souhaite que par défaut l’utilisateur sisr, crée des fichiers avec les permissions rw- r-- --- :
- Le premier nombre octal sera 0 (on ne change rien à rw-)
- Le second nombre (groupe) sera 2 (on supprime la permission w, donc 2, il reste r--)
- Le troisième nombre (others) sera 6 (on supprime r soit 4 et w soit 2, il reste ---)
Le umask de l’utilisateur sisr doit donc être 026

Sur un dossier, sans droits d’exécution, il est impossible d’agir dans le dossier, et les éventuels droits en écriture dans ce dossier ne seront pas appliqués.
De ce fait, les permissions “maximales” par défaut accordées à la création d’un dossier sont : rwx rwx rwx soit 777 en octal
Exemple: Le propriétaire doit disposer des droits complets sur le dossier, seulement des droits d’exécution et lecture pour le groupe, et aucun droits pour les autres. Ceci se traduit par : rwx r-x ---
Le umask de l’utilisateur devra retirer les droits en écriture sur le groupe (-2) et les droit rwx à others (-7). Le umask sera donc 027
Umask propose un comportement différent sur les fichiers et sur les dossiers. Mais cette valeur umask est la même pour les fichiers et les dossiers ! On utilise des valeurs “classiques” pour régler umask

Si l’on fait :

Jusqu’ici, nous avons précisé des valeurs sur trois chiffres en base octale. La commande umask affiche le umask de l’utilisateur actuel, mais sur 4 chiffres !
Le premier représente en faite les attributs spéciaux (setuid, setgid, sticky). Cependant, ces attributs spéciaux ne sont pas spécifiables par défaut (lors de la création d’un fichier ou dossier). Il n’est donc pas nécessaire de la préciser ou la calculer lors de l’utilisation de umask.
/!\ Umask n’est utilisé qu’à la création, les fichier existant ne sont pas touchés!
Gestion des archives
Une archive est un fichier contenant un ou plusieurs fichiers ou dossiers, la plupart du temps “compressés” ce afin de diminuer la
consommation d’espace disque. Il existe de nombreux algorithmes de compression et d’archivage, vous connaissez probablement le zip et le rar connu sous windows. Voyons certains des plus utilisés sous les système linux :
Tar
Tar est une très ancienne commande (Tape Archive), utilisée autrefois pour la sauvegarde de contenu sur des bandes magnétiques. Les
premières versions permettaient uniquement l’archivage, mais depuis l'arrivée de gzip (-z) et bzip2(-j) c’est maintenant possible.
Principaux attributs de tar (extension de fichier .tar en général):
- tar -c : Créer une archive
- tar -cf : Créer une archive et spécifier son nom
- tar -cvf : Créer une archive et afficher un diagnostic à l’écran
- tar -cvzf : Créer une archive, compresser avec gzip et afficher le diagnostic
- tar -tf : Lister (option t) le contenu de l’archive en argument (option f)
- tar -vtf : Lister (t) de façon détaillée (v) l’archive (f)
- tar -xf : Extraire (option x) le contenu de l’archive (f)
Gzip et gunzip
Par défaut l’utilisation de gzip remplace un fichier par sa version compressée ! qui aura l’extension “.gz”. Pour éviter ce comportement si l’on
veut conserver le fichier d’origine, on utilise l’option -c qui va rediriger le contenu extrait vers stdout !) il faudra donc faire soi-même la
redirection vers un fichier :
gzip -c monfichieraziper > monfichieraziper.gz
gzip -cr /etc > etc.gz
Gunzip quand à lui effectue l’opération inverse de gzip, il décompresse une archive gz. Et par défaut comme gzip, il remplace le fichier
d’origine “.gz” par sa version décompressé.
bzip2 et bunzip2
Le fonctionnement est similaire au gzip et gunzip, l'algorithme de compression utilisé est différent cependant. L’extension par défaut que l’on
rencontrera sera : bz2. L’option de récursion -r n’est pas disponible non plus, on utilisera le * à la place.
zip et unzip
Même si ce format est surtout utilisé sous windows, linux dispose de son équivalent :
zip ./test.zip ./test/* va compresser le contenu du dossier test dans le fichier test.zip
zip -r /etc/etc.zip /etc va compresser tout le contenu du dossier /etc
xz
xz -z * permet de compresser des fichiers individuellement (autant d’archives que de fichiers) avec l’extension .xz
xz -d permet de décompresser les fichier
cpio
cpio: copy-in copy-out
En mode copy-out (option -o), les fichiers dans un dossier seront recopiés vers une archive
En mode copy-in (option -i) le contenu d’une archive est listé ou copie les fichiers d’une archive vers un dossier.
dd
Permet d’effectuer la copie d’un fichier un d’une partition complète bit à bit. Cela permet de :
- Cloner un disque ou une partition
- Sauvegarder la MBR (master boot record)
- Création d’un fichier d’une taille précise rempli de 0
Recherche de fichier grâce aux commandes locate et find
locate et find sont les deux commandes principales pour chercher des fichiers dans la table d’inode de linux. Elles fonctionnent différemment
mais permettent le même résultat. Nous verrons aussi les commandes whereis / which / type
locate
Cette commande utilise une base de données mise à jour quotidiennement par l’OS. Si vous désirez mettre à jour cette base de données, vous
pouvez utiliser la commande updatedb
Les particularités de cette commande :
- N’affiche que les fichiers lisibles par l’utilisateur
- Très rapide pour la recherche, mais les fichiers récents seront absent à moins d’utiliser l’updatedb
- peut nécessité d’être installé apt-get install locate
Exemple : locate passwd

find
La commande a besoin de plusieurs choses pour travailler :
- Un nom de dossier comme point de départ de la recherche (sinon travail depuis le dossier courant)
- Pour rechercher un fichier on utilise l’option -name
- Plus lent que locate mais permet de se positionner où l’on veut et n’oubliera aucun fichier
exemple :

Vous remarquez qu’il y a beaucoup moins de fichiers, c’est qu’il faut utiliser le globing :
exemple : find / -name *passwd*
Voici différents options pour le find :
| Options | Exemple | Description |
| -iname | -iname Hello | recherche les fichiers en ignorant la casse |
| -mtime | -mtime -7 | Les fichiers modifiés il y a moins de 7 jours |
| -mmin | -mmin 5 |
Les fichiers modifiés il y a moins de 5 minutes |
| -size | -size +10M | Les fichiers pesant plus de 10Mo |
| -user | -user sisr | Les fichiers possédés par l’utilisateur sisr |
| -empty | -empty | liste les fichiers vides |
| -type | -type d | Liste les fichiers qui sont des dossiers |
| -maxdepth | -maxdepth 1 | Profondeur de recherche limité à 1, ne parcourt pas les sous-dossiers |
Si l’on veut tous les fichiers créés par l’utilisateur sisr qui s’appelle hosts :
find / -user sisr -name hosts
Ou une syntaxe plus compliquée :
find / -iname ‘ifconfig*’ -o \( -name hosts -user sisr \)
cette commande trouvera à partir du dossier racine :
- Tous les fichiers commençant par ifconfig
- OU Tous les fichiers intitulés hosts appartenant à l’utilisateur sisr
Pour définir sur quels attributs effectués un OU, il faut mettre les attributs entre parenthèses. Le problème c’est que le shell interprète la parenthèse comme un caractère spécial, il faut donc le protéger en utilisant \ devant chaque parenthèse pour dire au shell de ne pas l'interpréter mais de l’envoyer directement à la commande find. Le caractère \ est remplaçable par le ‘ find . -name host* -exec ls -l {} \;
- Trouver tous les fichiers commençant par host dans le dossier actuel et ses sous-dossiers
- Puis lancer la commande ls -l pour chaque fichier trouvé
- le {} permet de passer, fichier par fichier, la main à la commande ls
- Pour que ceci fonctionne, il faut rajouter un ; à la fin de chaque fichier passé en argument, donc \;
whereis et which

- whereis trouve deux binaire au nom de base
- which nous indique que seul bash est utilisé quand on utilise la commande base et non pas bash.bashrc. Ce dernier est un script
automatiquement lancé lorsqu'on se connecte à la ligne de commande en mode interactif.
type

Processus
Une commande sous linux crée un processus en mémoire, ce processus est sous la responsabilité du kernel. Tous les traitements effectués par une commande sont en fait traitées par le processus qui est créé lors de l'exécution de cette commande.
Un processus est exécuté (en général) par un utilisateur, il disposera donc des mêmes droits que l’utilisateur qui est responsable de son exécution. Et en général, un utilisateur ne pourra pas agir sur un processus lancé par un autre utilisateur, exception faite de root, évidemment.
La commande qui permet de lister les processus est PS :

PID : Numéro du processus (unique)
TTY : Nom du terminal dans lequel se trouve le processus
TIME : Le temps processeur utilisé par le processus
CMD : La commande qui a créé le processus
On peut déduire de cet exemple, qu’une même commande peut créer plusieurs processus.
Avec la commande ps x on peut voir dans quel état sont les processus

S: en sommeil
D : Sommeil irréversible
R : En cours d’exécution
T : Stoppé
Z : Zombie (processus terminé, mais pas encore totalement libéré)
Pour l’instant, on ne visualise que les processus de l’utilisateur, pour obtenir la liste complète, on va utiliser plutôt la commande :
ps -ef (-e tous les processus, et -f pour full détails)

Processus Foreground
Lorsque vous exécutez une commande comme ps -ef | less, le processus créé est foreground ou d’avant-plan. C’est-à-dire que le shell est bloqué durant l'exécution de la commande. L’utilisateur n’a donc plus la possibilité de faire autre chose. C’est pratique si le traitement est court, mais pas bon du tout si le traitement est long et coûteux en ressource.
Lorsqu'un processus a besoin de lancer un autre processus pour ses traitements, le premier processus est appelé processus parent et le ou les processus créés par le parent sont appelés processus enfant.
Lorsqu’un parent lancé en foreground crée un enfant, le processus enfant bloquera le parent jusqu’à la fin de ses traitements, puis à sa mort, le parent reprendra le relais.
Par exemple, le bash est un processus. Quand on lance une commande dans le bash, le processus parent bash est bloqué jusqu’à la fin des traitements de son processus enfant (par exemple le ls)
Si vous voulez éviter de bloquer le shell (ou le parent). Il est possible de lancer une commande en tâche de fond, dans ce cas, l’enfant rendra immédiatement les droits de continuer les opérations au parent, tout en continuant de faire ses traitements.
Pour se faire, on utilisera le caractère &, par exemple :

ici :
[1] représente le numéro du travail ou “job”.
1342 représente le PID créé pour ce travail
Ces deux informations apparaissent automatiquement lors de la création d’un processus en tâche de fond
[1] Fini signifie que le job 1 est terminé et bash rappel quelle commande avait été exécutée.
Déplacer un processus
Si l’on fait un script, dont une commande demande à dormir 10.000 secondes, mais malheureusement, j’ai oublié de demander à la commande du script de se lancer en tâche de fond

- Le ctrl+z permet d'interrompre le processus (suspend)
- on fait la commande bg, qui passe le processus en tâche de fond
- on le remet en foreground avec la commande fg
- le ctrl+c permet de lancer une interruption logiciel qui envoi un SIGTERM au processus en foreground
Si vous voulez connaître la liste des jobs en cours de traitement, vous pouvez utiliser la commande jobs

Signaux
Un signal est un message envoyé à un processus pour altérer son état (par exemple stop, start, pause)
Certains signaux peuvent s’envoyer avec un raccourcis clavier (ctrl+z stoppe un processus)
Pour consulter la liste des signaux, kill -l

Donc la commande kill permet d’envoyer un signal à un processus de plusieurs façons :
- Kill -2 → envoi le signal 2 (SIGINT) à un processus
- Kill -SIGINT → envoi le signal SIGINT à un processus
Le SIGINT est l’équivalent du CTRL+Z (stoppe le processus mais ne le détruit pas)
Pour tuer (détruire) un processus, on utilisera plutôt le SIGTERM (15)

Killall - tuer un processus par user
La commande killall -u permet de demander à tuer tous les processus appartenant à un utilisateur.
killall -u root
Supprimera tous les processus lancés par le compte root.
Conserver un processus en quittant
Quand un utilisateur se déconnecte de sa session, tous les processus rattachés à l’utilisateur reçoivent un SIGHUP (1) qui va finalement tuer
tous les processus rattachés.
Si l’opération de sauvegarde est très longue et que l’administrateur doit se déconnecter, sa sauvegarde s’arrêtera par exemple.
Pour éviter ce phénomène, on utilisera la commande nohup
Priorité d’un processus
Un processus a besoin de temps processeur pour faire ses calculs. Certains d’entre eux ont droits à plus de CPU que d’autres, ceci se règle
avec un mécanisme de priorité. Les processus lancés par le système auront en général plus de priorité que les autres.
C’est le kernel qui s’occupe d’ajuster dynamiquement la priorité et essaie de fournir les bonnes priorités selon les besoins.
L’utilisateur pourra influencer dans une certaines mesure cette priorité en faisant varier une valeur de “gentillesse” niceness !
niceness -20 => Donne la priorité la plus haute possible
niceness 0 => valeur par défaut
niceness 19 => priorité la plus basse
Un utilisateur standard aura le droit de régler l’indice entre 19 et 0. Seul le root peut faire des réglages entre -1 et -20.
Pour affecter un indice de gentillesse, on utilise la commande nice avec l’option -n (régler la gentillesse) et une valeur.

Sur les captures précédentes, on a vu des + et des - à côté des jobs, les jobs avec un + est le dernier job à avoir été placé en tâche de fond.
Celui avec un - est l’avant-dernier.
Vous pourrez utiliser la commande TOP pour lister les tâches en cours.
Cron
Le démon crond est le processus qui permet d’exécuter des tâches planifiées automatiquement à des instants précis prévus à l’avance (date,
heure, minute) et en gérant une chronicité.
Si par exemple je veux qu’une machine PC-560 s’éteigne tous les jours à 20h51, je peux le faire avec cron. Pour cela, il me faut une entrée
dans la crontab de la machine qui indiquera la commande à exécuter pour éteindre la machine.
Normalement, cron est installé par défaut sur les systèmes, sinon vous pouvez l’installer comme d’habitude.
Toutes les configurations exécutées par cron vont se retrouver dans la table de cron (crontab). Seul la syntaxe particulière est complexe à
utiliser.
Utilisation de la crontab
Pour paramétrer une tâche planifiée, il faut écrire une entrée dans la crontab. Cette entrée spécifie la (ou les) date d’exécution de cette tâche,
ainsi que la tâche à exécuter et d’autres paramètres si nécessaire.
Pour chaque utilisateur du système, on peut éditer un fichier de crontab, relatif aux tâches planifiées de ce dernier. Ces fichiers se trouvent en
général dans “/var/spool/cron/crontabs/” ou un équivalent et portent le nom de l’utilisateur en question.
L’édition du fichier ne se fait pas en direct dans le spool, on utilisera une commande dédié pour ça :
- crontab -e pour éditer le fichier de crontab de l’utilisateur courant
- crontab -e -u root pour éditer la crontab d’un utilisateur spécifique (root)
- crontab -l pour afficher la crontab de l’utilisateur courant.
- crontab -r qui va effacer la crontab de l’utilisateur
En général au premier lancement, le système vous demandera quel moteur de texte vous souhaitez utiliser (nano, vi, ...) en fonction de ceux
installé. En sortie du fichier, le système vérifiera que la syntaxe de vos entrées est correct.
Il est important de noter, que le système dispose, en plus du crontab utilisateurs, de ses propres fichiers et tâches planifiées dans les
répertoires “/etc/cron.*” l’étoile représente les différents dossiers utilisés (qui sont référencés dans /etc/crontab) :
- cron.hourly toutes les heures
- cron.daily tous les jours
- cron.weekly toutes les semaines
- cron.monthly tous les mois
- cron.d contient des fichiers au format crontab pour des utilisations plus spécifiques.
Syntaxe de cron
Chaque entrée dans la crontab correspond à une tâche à exécuter. Et chaque entrée de la crontab est une ligne dans un des fichiers cités plus
haut. Si nous regardons une ligne en détail :
Exemple :51 19 * * 0 root /usr/local/bin/backupbackup
Cette ligne signifie de lancer le programme /usr/local/bin/backupbackup tous les dimanches à 19h51.
La syntaxe générale d’écrit sous cette forme :
mm hh jj MMM JDS commande
mm : Codé sur 2 chiffres représente les minutes de 0 à 59, ou * pour décrire toutes les minutes
hh : Codé sur 2 chiffres représente les heures de 0 à 23, ou * pour décrire toutes les heures
jj : Codé sur 2 chiffres représente la date du jour de 1 à 31, * pour décrire tous les jours
MMM : Codé sur 2 chiffres ou 3 lettres représente le mois de 1 à 12 ou de jan à dec, * pour décrire tous les mois
JDS : représente le jour de la semaine codé par 1 chiffre ou 3 lettres (de 0 à 7 ou de sun à sun, le 0 et le 7 représente sunday)
commande : la commande qui sera exécutée.
On peut trouver des caractères spéciaux dans les champs prévus pour :
- * : signifie tout ou chaque unité de temps.
- , : permet de décrire une liste. Exemple 3,5,17
- - : permet de décrire un intervalle. Exemple de 1 à 10 se note 1-10
- */ : permet de décrire un intervalle avec des pas différents de 1. Par exemple : */10 signifie 0,10,20,30, ...
- @reboot : permet de lancer la commande au démarrage de la machine
- @yearly : tous les ans
- @daily : tous les jours
Vous pouvez également vous renseigner sur anacron, pour que les tâches soient exécutées même si la machine est éteinte (ou au moins au
redémarrage de celle-ci).
Commande Sed
La commande sed fonctionne en mode flux ligne par ligne, le flux d’entrée peut-être aussi bien un fichier, qu’un pipe.
Sed peut s’utiliser de deux façons :
- La méthode “classique”, qui consiste à appliquer la commande sur le flux d’entrée, et de récupérer le flux de sortie. Par exemple, on applique sed sur un fichier et on redirige la sortie sur un autre fichier
- La méthode “directe”, avec l’option sed -i, qui applique la commande directement sur le fichier passé en entrée.
Il existe encore deux manières de passer un script à sed :
- Ecrire le script directement dans la ligne de commande, avec l’option sed -e. On séparera les commandes avec des “;” c’est la façon “uniligne”, souvent très pratique
- On peut passer à sed un fichier externe “monscript.sed” par exemple, qui contient le script, grâce à sed -f script_files. Cela assure une meilleure lisibilité pour les gros scripts et permet aussi de réutiliser un script.
Adressage par ligne
Prenons un fichier d’exemple suivant :

Si l’on utilise un sed ‘4d; 7d’ test.txt, on obtiendra

On a supprimé la ligne 4 et la ligne 7. (d=delete)
Si l’on a utilisé une “,” avec la commande sed ‘4,7 d’ test.txt

On a supprimé les lignes comprise entre la ligne 4 et la ligne 7
Adressage par motif
ex : sed ‘/system/!d’ test
Notre regex contient le schéma de recherche ‘system’, et les “/” permettent de délimiter le schéma. Cette regex ne sert pas à grand chose, car on recherche un mot précis, mais nous allons voir qu’avec, on peut chercher et récupérer des syntaxes beaucoup plus complexes.
Le langage contient bon nombre de caractères avec un sens spécifique qui permettent des recherches très pointues. Tout d’abord nous allons parler des fonctions qui permettent de définir des traitements de recherche pour la commande sed. Si l’on utilise, par exemple, l’option ‘!d’, le sed ne nous sortira que les ligne contenant le pattern recherché, nous placerons les options en fin de regex.
Pour notre fichier de test qui contient la liste des utilisateurs :

sed ‘/system/!d’ nom_fichier
donnera la sortie suivante :

Les différentes fonctions de la commande sed où l’on peut utiliser des motifs sont :
(Attention, sed peut être utilisé sans motif pour sélectionner des lignes ou des ensembles de ligne, je vous laisse vous reporter au man, pour plus de détails.)
| Fonction | Exemple | Description |
| d | sed ‘/system/d’ fichier | Supprime de la liste toutes les lignes qui correspondent au pattern de recherche |
| !d | sed ‘/system/!d’ fichier | Supprime de la liste toutes les lignes qui ne correspondent pas au pattern de recherche |
| -n et p | sed -n ‘/system/p’ fichier | Le mode silencieux -n permet de dire à la commande sed de n’afficher aucune lignes, seules les lignes intéressantes seront affichées grâce à l’option print “p” |
| -n et = | sed -n ‘/system/=’ fichier | Permet d’obtenir les numéros de lignes |
| -l et l | sed -n ‘/system/l’ fichier | Affiche la ligne sélectionnée avec en plus les caractères de contrôles en clair avec leur code ASCII |
| , | sed -n ‘/network/,/resolve/’ fichier | On recherche un interval, donc toutes les lignes comprises entre les 2 motifs qui sont séparés par la virgule |
| q (quit) | sed ‘/system/q’ fichier |
Va lister le fichier jusqu’à trouver le pattern et s’arrêter |
| -r | sed -r |
Permet d’utiliser la syntaxe étendue |
| -e | sed -e |
Permet d’écrire un script directement en ligne de commande |
| s (substitution) |
sed -re 's/^# *//' fichier |
Permet de substituer le premier motif par le deuxième, ici, on remplace les # suivis d’espace en début de ligne par rien |
| y (translitération) |
sed -re ‘y/éèê/eee/’ fichier |
Permet de remplacer certains caractères par d’autres caractère |
Commande Awk
Cette commande agit comme un filtre programmable, prenant une série de lignes en entrée (par fichier, ou via l’entrée standard) et écrivant sur la sortie standard (redirigeable). Awk prend en entrée les lignes une par une et choisit les lignes à traiter (ou non) par des expressions rationnelles ou des numéros de lignes. Une fois la ligne sélectionnée, elle est découpée en champs, selon un séparateur d’entrée indiqué dans le programme awk par le symbole FS (par défaut espace et tabulation). Puis les différents champs sont disponibles dans les variables ($1, $2, $3, $NF pour le dernier). Vous pourrez aussi trouver des fichiers .awk qui sont des scripts écrits dans ce langage.awk [-F] '{action-awk}' [ fichier1 fichier2 ..... fichiern ]
La commande prend en paramètre la liste des fichiers à traiter, si des fichiers ne sont pas spécifiés, awk travaillera sur l’entrée standard. On peut donc placé la commande derrière un tube de communication. L’option “-F” permet d'initialiser si besoin la variable “FS” (Field Separator).
Voici une liste des variables prédéfinies au lancement de awk:
| Variables | Valeur par défaut | Rôle |
| RS | Newline (\n) |
Record Separator : Caractère séparateur d’enregistrement (lignes) |
| FS | Suite d’espaces et ou de tabulation | Field Separator : caractères séparateurs de champs. |
| OFS | Espace |
Output Field Separator: Séparateur de champ pour l’affichage |
| ORS | Newline (\b) |
Output Record Separator : Séparateur de ligne pour la sortie |
| ARGV | - |
Tableau initialisé avec les arguments de la ligne de commande (awk inclus) |
| ARGC | - | Nombre d’arguments dans le tableau ARGV |
| ENVIRON | Variables d’environnement exportées par le shell | Tableau contenant les variables d’environnement exportées par le shell. |
| CONVFMT | %.6g | Format de conversion des nombres en string |
| OFTM | %.6g | Format de sortie des nombres. |
| SUBSEP | \0.34 |
Caractère de séparation pour les routines internes de tableaux. |
Attention : Lorsque que la variable FS a plus de 2 caractères, elle sera interprété comme une expression régulière
Voici les variables qui sont initialisées lors du traitement d’une ligne
| Variable | Rôle |
| $0 | Valeur de l’enregistrement courant |
| NF | $1 contient la valeur du 1er champ, $2 du 2ème, ... et $NF le dernier |
| $1,$2, .. $NF |
$1 contient la valeur du 1er champ, $2 du 2ème, ... et $NF le dernier |
| NR |
Number : indice de l’enregistrement courant (NR vaut 1 quand la 1ère ligne est en cours de traitement) |
| FNR |
File Number : indice de l’enregistrement courant relatif au fichier en cours de traitement |
| FILENAME |
Nom du fichier en cours de traitement |
| RLENGTH |
Longueur en string trouvé par la fonction match() |
| RSTART |
Première position du string trouvé par la fonction match |
Exemple d’utilisation :ps -ef| awk ‘{print $1,$8}’
avec ps -ef on a la liste des processus, en cours d’exécution (voici un extrait):

et avec la commande:

La partie en gras représente entre quote permet d’éviter l’interprétation par le shell et indique à awk quelle fonction exécuter sur le traitement du awk. Les instructions doivent être placées entre accolades. La fonction intégrée print va afficher à l’écran les champs 1 et 8 de chaque ligne.
Voici un autre exemple :ps -ef | awk ‘{print “User : “, $1, “\tCommande : “, $8}’

Critères de sélection :
Il est possible de sélectionner les enregistrements sur lesquels l’action doit être exécutée : awk [-F] 'critère {action-awk}' [fichier1 fichier2 ... fichiern]
Le critère de sélection peut s’exprimer de différentes manières.
Expression régulières :awk -F’:’ ‘/\/bin\/false/ {print $0}’ /etc/passwd

Par défaut, c’est le champ correspondant au $0 qui est mis en correspondance avec
l’expression régulière., mais il est possible de le spécifier avec l’opérateur de concordance
“~” ou de non concordance “!~”.
awk -F ':' '$6 ~ /^\/usr/ {print $0}' /etc/passwd

Test logiques :
Le critère peut être une expression d’opérateurs renvoyant vrai ou faux.
Par exemple, pour afficher uniquement les lignes impaires du fichier /etc/passwdawk -F':' 'NR%2 {print $0}' /etc/passwd
DHCP sur Debian
NB: Le tuto à été fait du temps de Debian 7, j'ai modifié les commandes pour que le tuto soit d'actualité, il est donc possible que les screens ne correspondent pas exactement à la commande cité
L'objectif de ce tutoriel est d'apprendre à mettre en place un serveur DHCP sous Linux.
Un serveur DHCP (Dynamic Host Configuration Protocol) a pour rôle de distribuer de façon automatique, des adresses IP à des clients pour une durée déterminée.
Au lieu d'affecter manuellement à chaque hôte une adresse statique, ainsi que tous les paramètres tels que (serveur de noms, passerelle par défaut, nom du réseau), un serveur DHCP alloue à un client, un bail d'accès au réseau, pour une durée déterminée (durée du bail). Le serveur passe en paramètres au client toutes les informations dont il a besoin.
Pour cela, j'ai utilisé 3 VMs:
- Une VM Debian
- Une VM Windows 10
- Une VM Windows Serveur 2016
DHCP de base
Partie Debian
Premièrement faire les mises à jour:
apt-get update
apt-get upgradeTélécharger le paquet dhcp-serveur
apt-get install isc-dhcp-serverUne fois tous les paquets nécessaires installés, je passe mon Vcom de Ext a Privé (pour que les VMs puissent parler entre elles). Je configure mon réseau pour qu’il soit en 192.168.0.0:
ip a (pour voir les paramètres de la carte actuellement)
On a bien notre nouvelle IP, qui correspond au réseau des VM On peut aussi passer par le fichier de configuration qui se trouve ici:
nano /etc/network/interfaces
On peut voir le loopback network, qui nous sera pas utile dans ce cas la. En dessous, on peut voir deux lignes qui concernent le eth0, notre carte réseau. Nous allons remplacer la dernière ligne (iface eth0 inet dhcp) par:

Ces lignes nous permettent de passer à une IP statique, au lieu de demander à un DHCP. Attention ! Pour que la configuration soit prise en compte, il faut redémarrer l’interface réseau. Pour cela:
systemctl restart networking
Pas de eth0 en vu ?! Pas de soucis, il suffit de faire la commande:
ifup eth0
Et la revoilà ! Maintenant nous allons attaquer vraiment le DHCP. Pour cela, on va commencer par le configurer:
nano /etc/dhcp/dhcpd.confNous allons modifier quelques lignes dans ce fichier:

Ici, nous avons le domaine dans lequel se rattache la VM, et les DNS à utiliser. Vu que nos VM en sont qu'à leur début, je me contente du domaine que j’ai mis à l’installation, et des DNS Google.

Voila la partie qui concerne notre futur DHCP. Subnet est le nom du réseau, netmask le masque. Range est la plage qu'on veut attribuer à notre DHCP. Ici, les VM auront une IP de 192.168.0.10 à 192.168.0.20. Option router correspond à la passerelle. N’oubliez pas de décommenter (= enlever les # en début de ligne) les lignes que vous avez modifiés. Vous pouvez sauvegarder (ctrl X, O, entrée) Pour prendre en compte les changements, il faut redémarrer le service DHCP:
systemctl restart isc-dhcp-server Voila, le DHCP est fini !
Partie Windows (La VM qui utilise le DHCP)
Avant de faire ça, pensez à mettre le Vcom de votre VM en privé, pour que les VMs communiquent entre elles. Une fois le serveur mis en place, il suffit d'ouvrir un cmd (WIN +R, cmd) et taper ces commandes:
ipconfig /release
Ici on peut voir que la VM n’a plus d’IP, on va lui en donner une avec:
ipconfig /renew
Windows va aller chercher automatiquement sa nouvelle ip via le DHCP. Et voilà ! Notre VM Linux a donné une IP à notre Windows 10!
DHCP avancé: Réservation DHCP
Dans certains cas, il est important que l’adresse IP d’une machine soit toujours la même. Nous allons voir comment fixer une IP à une machine.
Il faut d’abord retrouver l’adresse MAC de la machine concerné. Pour cela, deux façon de faire:
- En passant par le Centre réseau et partage:

- Ou bien via le cmd en tapant la commande getmac:

Dans notre cas, l’adresse MAC est: 00-15-5D-04-21-07 Une fois l’adresse MAC notée, on ouvre le fichier de configuration du DHCP sur la VM Linux:

Lithium correspond au nom de la machine (mais vous pouvez mettre ce que vous voulez), hardware ethernet correspond à l’adresse MAC de la machine, et fixed-address est l’IP qu’on veut attribuer à la machine. Sauvegardez, et redémarrez le service avec:
systemctl restart isc-dhcp-server Coté Windows, il suffit de faire dans le cmd:
ipconfig /release
Ici on peut voir que la VM n’a plus d’ip, on va lui demander de chercher son IP avec:
ipconfig /renew
Et voilà, la VM a son IP fixé par le DHCP !
DHCP avancé: Multi réseau
Dans certains cas, il peut exister plusieurs réseau différents, mais qui doivent être gérés par le DHCP. Nous allons voir comment configurer le DHCP pour qu’il puisse gérer deux réseaux distincts. Tout d’abord, il faut rajouter une carte réseau à notre VM Linux. Pour cela, après l’avoir éteint, il faut aller dans les paramètres de la VM,ajouter un matériel, et carte réseau

Une fois la carte configurée (Je créé un nouveau réseau, appelé réseau public), je peux relancer ma VM Je fais un ifconfig voir si j’ai bien mes deux cartes réseau:

Pas de eth1 en vue ? Essayez la commande suivante:
ifup eth1
Et la voilà ! Il faut ensuite la configurer, exactement comme au début du tuto (mais avec un réseau différent !)

J’ai désormais deux réseaux différents, sur eth0 192.168.0.0 et sur eth1 192.168.1.0. Passons à la configuration du DHCP:
nano /etc/dhcp/dhcpd.confEn dessous de mon premier réseau, je vais ajouter le nouveau:

Une fois cela fait, il faut redémarrer le service:
systemctl restart isc-dhcp-server Côté Windows, je change mon Vcom pour passer dans le “Réseau Public” Je relance mes deux commandes:
ipconfig /release
ipconfig /renew
Ma VM est désormais dans l’autre réseau !
Maintenant vous savez faire un DHCP directement sur Debian ! A bientôt pour d'autres tutos ;)
Installation de Nextcloud
Note: ce tutoriel ne fonctionne qu'avec Debian 10. Si vous êtes en Debian9, il faudra changer le sources.list et mettre la dernière version (trouvable ici: https://wiki.debian.org/fr/SourcesList)
Installation:
Après un apt update/upgrade, il faut tout d'abord installer mariadb:
apt install mariadb-server
Une fois l'installation complète, faites la commande suivante:
mysql_secure_installation
L'interface va vous poser plusieurs questions, à vous d'y répondre en fonction de vos besoins
Vous devez créer maintenant une base de données pour le Nextcloud:
$ mysql
> CREATE USER 'adminDB'@'localhost' IDENTIFIED BY '$PMAmdp%';
> GRANT ALL PRIVILEGES ON *.* TO 'adminDB'@'localhost' WITH GRANT OPTION;
> FLUSH PRIVILEGES;
> exit
Une fois la base de données crée, vous pouvez installer toutes les dépendances:
apt install curl apache2 php php-mysql php-mbstring php-gd php-json php-curl php-mbstring php-intl php7.1-mcrypt php-imagick php-xml php7-zip
Vous pouvez maintenant télécharger le .zip nextcloud
wget https://download.nextcloud.com/server/releases/nextcloud-16.0.4.zip
On le dezip:
unzip nextcloud-16.0.4.zip
On le déplace dans le dossier html:
mv nextcloud /var/www/html
Donnez les droits à l'user www-data:
chown -R www-data:www-data /var/www/html
Vous pouvez désormais y accéder via votre navigateur:
http://ip/nextcloud
Et voila: plus qu'à configurer la base de données précédemment crée, et vous avez votre Nextcloud !
Création du certificat:
Nb: Dans ce cas là, ce certificat est un auto signé, c'est à dire que votre site sera sécurisé, mais votre navigateur ne reconnaîtra pas le certificat et vous affichera un message d’erreur
On commence par créer un dossier pour stocker un certificat:
cd /var/www/html
mkdir cert
On généré la clé:
openssl genrsa -out cert/key.key 1024
Avec la clé, on généré le certificat:
openssl req -new -x509 -days 365 -key cert/key.key -out cert/cert.crt
Pour pouvoir avoir le ssl de disponible, il faut activer le module SSL. Pour cela il faut faire la commande suivante:
a2enmod ssl
Et on redémarre apache
systemctl restart apache2
On modifie le vhost ssl

On redémarre Apache, et votre site est en https !

Si vous avez besoin d'un certificat reconnu, vous pouvez utiliser le site suivant:
Installation de GLPI
Présentation
GLPI (Gestionnaire Libre de Parc Informatique) est un logiciel libre de gestion des services informatiques et de gestion des services d'assistance.
Parmi ses caractéristiques, cette solution est capable de construire un inventaire de toutes les ressources de la société et de réaliser la gestion des tâches administratives et financières. Les fonctionnalités de cette solution aident les administrateurs informatique à créer une base de données regroupant des ressources techniques et de gestion, ainsi qu’un historique des actions de maintenance. La fonctionnalité de gestion d'assistance ou helpdesk fournit aux utilisateurs un service leur permettant de signaler des incidents ou de créer des demandes basées sur un actif ou non, ceci par la création d'un ticket d’assistance.
Prérequis
GLPI est une application web. Nous allons l’installer sur Debian 9, et nécessite donc plusieurs paquets:
-
- Apache 2
- Php et ses dépendances
- MySQL, qui peut être soit en local, soit en déporté sur un autre serveur
Installation de base
On fait d’abord les mises à jours
apt-get update && apt-get upgradeOn installe ensuite tous les paquets nécessaire
apt-get install apache2 php php-gd php-mysql mysql-server php-mbstring php-curl php-xmlInitialisation de la base de données
Pour créer une base de donnée il faut d'abord rentrer dans la console mysql:
$ mysql -u root -pOn crée la base de donnée bddglpi
> create database bddglpi character set utf8;On donne tous les privilèges sur la bddglpi à l’user glpi avec le mot de passe glpi
> grant all privileges on bddglpi.* to glpi@localhost identified by 'glpi';
> exitInstallation de GLPI
Pour télécharger GLPI nous devons d’abord récupérer le code source compressée
wget https://github.com/glpi-project/glpi/releases/download/9.3.3/glpi-9.3.3.tgzPour le décompresser
tar xzvf glpi-9.3.3.tgzOn déplace ensuite le dossier GLPI vers le dossier web
mv glpi /var/www/htmlPour finir, on ajoute les droit à l’utilisateur apache pour qu’il puisse l’afficher et le modifier
chown -R www-data /var/www/html/glpiConfiguration de GLPI









Serveur Asterisk
Petit Serveur sans prétention Asterisk (FreePBX à venir).
Serveur Asterisk en ligne de commande
Dans un premier temps, faire une mise à jour du système.
apt-get update && apt-get upgrade -y
Puis nous procédons à l'installation des packages nécessaires
apt-get install -y build-essential linux-headers-`uname -r` openssh-server apache2 mysql-server mysql-client bison flex php5 php5-curl php5-cli php5-mysql php-pear php-db php5-gd curl sox libncurses5-dev libssl-dev libmysqlclient15-dev mpg123 libxml2-dev libnewt-dev sqlite3 libsqlite3-dev pkg-config automake libtool autoconf git subversion
Installation de PearDB
pear install db
un petit reboot serverreboot
Installation des dépendances pour les voix google.
Installation d'iksemel
cd /usr/src
wget https://iksemel.googlecode.com/files/iksemel-1.4.tar.gz
tar xf iksemel-1.4.tar.gz
cd iksemel-1.4
./configure
make
make install
Téléchargement des Sources
cd /usr/src
wget http://downloads.asterisk.org/pub/telephony/dahdi-linux-complete/dahdi-linux-complete-current.tar.gz
wget http://downloads.asterisk.org/pub/telephony/libpri/libpri-1.4-current.tar.gz
wget http://downloads.asterisk.org/pub/telephony/asterisk/asterisk-11-current.tar.gz
Compilation et installation de DAHDI.
tar xvfz dahdi-linux-complete-current.tar.gz
cd dahdi-linux-complete-2.6.1+2.6.1
make all
make install
make config
Compilation et installation de LIBPRI
cd /usr/src
tar xvfz libpri-1.4-current.tar.gz
cd libpri-1.4.14
make
make install
Compilation et installation d'Asterisk
cd /usr/src
tar xvfz asterisk-11-current.tar.gz
cd asterisk-11.1.0
./configurecontrib/scripts/get_mp3_source.sh
make menuselect
make
make install
make config
Installation Asterisk-Extra-Sounds
cd /var/lib/asterisk/sounds
wget http://downloads.asterisk.org/pub/telephony/sounds/asterisk-extra-sounds-en-gsm-current.tar.gz
tar xvfz asterisk-extra-sounds-en-gsm-current.tar.gz
rm asterisk-extra-sounds-en-gsm-current.tar.gzVoila
Ce tutoriel date un peu (debian 8), je ferais un petit test pour voir si il est toujours fonctionnel sur Debian 10 et Raspberry.
Installation d'un serveur Asterisk avec dépôt
Installation de Asterisk
On fait d’abord un update des dépôts Attention cela n'est pas une mise à jour du système
apt updateOn installe ensuite le paquet nécessaire
apt install asterisk Voilà votre serveur asterisk est installé la méthode ou il faut compiler n'est pas utile fonctionne sur Debian 9 & 10 pas certain mais aussi sur le 8
Failover avec Hearbeat, rsync et réplication mysql
Pour mieux expliquer ce TP, j'ai pris un exemple concret: une installation de Wordpress, qui nous permettra de tester la réplication des fichiers et de la BDD !
Prérequis :
- Installer Debian 10 et ses mises à jour
- Cloner la VM pour en créer une autre, identique
- Renommer le clone /etc/hostname
- Configurer les IP statiques sur les 2 VM
- Choisir une IP virtuelle pour le cluster
Installation d'Heartbeat
(a faire sur chaque node)
apt install heartbeatCréation du fichier de configuration:
nano /etc/heartbeat/ha.cfAjoutez les paramètres suivants:
# Indication du fichier de log
logfile /var/log/heartbeat.log
# Les logs heartbeat ne seront pas gérés par syslog
logfacility none
# On liste tous les membres de notre cluster heartbeat (par les noms de préférences)
node NOM_DU_NODE1
node NOM_DU_NODE2
# On défini la périodicité de controle des noeuds entre eux (en seconde)
keepalive 1
# Au bout de combien de seconde un noeud sera considéré comme "mort"
deadtime 10
# Quelle carte résau utiliser pour les broadcasts Heartbeat (ens33 dans mon cas)
bcast ens18
# Adresse du routeur pour vérifier la connexion au net
ping 10.10.1.254
# Rebascule-t-on automatiquement sur le primaire si celui-ci redevient vivant ? oui*
auto_failback yesCréation du fichier de clé:
nano /etc/heartbeat/authkeysAjoutez les paramètres suivants:
auth 1
1 sha1 UneCleÉdition des droits sur le fichier:
chmod 600 /etc/heartbeat/authkeysCréation du fichier haressources:
nano /etc/heartbeat/haresources On indique le nom du node primaire et son IP
NODE1 10.10.1.127Démarrage d'Heartbeat:
systemctl start heartbeatSi tout se passe bien, sur le premier node l'IP virtuel apparaît

Installation de Wordpress
(Vous pouvez passer cette étape si vous avez votre propre site)
Idem, à faire sur les deux nodes
Installation du serveur LAMP:
apt install apache2 mariadb-server php libapache2-mod-php php-cli php-common php-curl php-gd php-json php-mbstring php-mysql php-xml php-xmlrpc php-soap php-intl php-zipCréation de la base de donnée:
mysql -u root -p
CREATE DATABASE wordpress DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci;
GRANT ALL ON wordpress.* TO 'wordpress_user'@'localhost' IDENTIFIED BY 'password';
FLUSH PRIVILEGES;
EXIT;Téléchargement et décompression de WordPress:
cd /tmp
wget https://wordpress.org/latest.tar.gz
tar xzvf latest.tar.gzCréation du fichier .htaccess
touch /tmp/wordpress/.htaccessCopie du fichier config exemple en fichier config :
cp /tmp/wordpress/wp-config-sample.php /tmp/wordpress/wp-config.phpCopie du dossier temporaire vers le dossier définitif :
cp -a /tmp/wordpress/. /var/www/html/wordpressDonner les permissions au dossier /wordpress :
chown -R www-data:www-data /var/www/html/wordpressConfigurer le fichier de config Wordpress :
nano /var/www/html/wordpress/wp-config.phpRemplacer :
- database_name_here
- user_name_here
- password_here
- régler la collation de la base de donnée comme configurée plus tôt
Redémarrer Apache, se connecter via navigateur, vérifier que le site wordpress est accessible. (Sur les deux Nodes)
Ne finissez pas la configuration de WordPress !
Réplication du dossier de l’application avec Rsync
Synchronisation des dossiers wordpress avec Rsync
Installation de Rsync (par defaut il y est deja, au cas ou)
apt install rsyncTest de Rsync à partir du Node secondaire :
rsync --delete -avzhe ssh root@10.10.1.167:/var/www/html/wordpress/ /var/www/html/wordpress/Mise en place du login SSH sans mot de passe, par certificat, sur le node secondaire :
ssh-keygen -t rsa -b 2048
ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.10.1.158Test de la connexion sans mot de passe
ssh root@10.10.1.158Vous avez accès directement au shell sans rentrer de mot de passe
Automatisation de la synchro entre les deux Nodes :
Créer un script /scripts/rsync.sh
Y coller la commande rsync précédente
Si besoin on ajoute les droits d’exécution:
chmod +x rsync.shOn ajoute la cron:
crontab -e
On teste en créant un fichier dans le dossier wordpress sur le Node principal, il devrait être créé sur le Node secondaire moins d’une miute après.
On le supprime et on vérifie qu’il soit bien supprimé.
Réplication des bases de donnée :
Sur le Node principal (base Master) :
On active les binary logs
mysql -u root -p
SET sql_log_bin = 1;
exitA la fin du fichier /etc/mysql/my.cnf an ajoute les paramètres suivants :
[mariadb]
log-bin
server_id=1
log-basename=master1On redémarre le service MySQL
systemctl restart mysqlOn crée un utilisateur pour la réplication :
CREATE USER 'replication_user'@'%' IDENTIFIED BY 'repli_password';
GRANT REPLICATION SLAVE ON *.* TO 'replication_user'@'%';Sur le Node secondaire :
Même principe, a la fin du fichier /etc/mysql/my.cnf an ajoute les paramètres suivants (pensez à changer l'ID):
[mariadb]
log-bin
server_id=2
log-basename=master1On redémarre le service MySQL
systemctl restart mysqlOn configure la base en esclave :
mysql -u root -p
CHANGE MASTER TO
MASTER_HOST='10.10.1.158',
MASTER_USER='replication_user',
MASTER_PASSWORD='repli_password',
MASTER_PORT=3306,
MASTER_CONNECT_RETRY=10;On démarre le mode esclave :
START SLAVE;On vérifie l’état de la synchronisation :
SHOW SLAVE STATUS;
Si la synchronisation est fonctionnelle, on peut tester en terminant la configuration sur le Node primaire. Celle ci devrait s’appliquer automatiquement sur le Node secondaire.
On crée un article Wordpress, il devrait être dupliqué sur le second serveur.
Voila, votre site web est répliqué !
Migration d'un serveur GLPI
Le serveur GLPI est sur une Debian 7.11 et en version 9.1.
Création d'un nouveau serveur en Debian 10 avec la dernière version de GLPI 9.4.6
Préparation du nouveau système
Je vous passe la création d'une VM sous Debian 10.
Modification du source.list
/etc/apt/source.list
# deb cdrom:[Debian GNU/Linux 10.4.0 _Buster_ - Official amd64 NETINST 20200509-10:25]/ buster main
deb http://deb.debian.org/debian/ buster main contrib non-free
deb-src http://deb.debian.org/debian/ buster main contrib non-free
deb http://security.debian.org/debian-security buster/updates main contrib non-free
deb-src http://security.debian.org/debian-security buster/updates main contrib non-free
# buster-updates, previously known as 'volatile'
deb http://deb.debian.org/debian/ buster-updates main contrib non-free
deb-src http://deb.debian.org/debian/ buster-updates main contrib non-free
# Backports repository
deb http://deb.debian.org/debian buster-backports main contrib non-free
#deb http://deb.debian.org/debian buster-backports-sloppy main contrib non-free Installation des paquets de base
apt install -y \
apt-transport-https \
bash-completion \
curl \
dnsutils \
git \
htop \
locate \
net-tools \
openssl \
open-vm-tools \
python3-pip \
ssl-cert \
sudo \
telnet \
traceroute \
tuned \
v4l2loopback-utils \
wget \
unzip MariaDB
Dépôt officiel
apt install software-properties-common dirmngr
apt-key adv --fetch-keys 'https://mariadb.org/mariadb_release_signing_key.asc'
add-apt-repository 'deb [arch=amd64] http://ftp.igh.cnrs.fr/pub/mariadb/repo/10.4/debian buster main' Installation de MariaDB
apt install -y mariadb-client mariadb-server Sécurisation MariaDB
mariadb-secure-installation
Enter current password for root (enter for none):
Switch to unix_socket authentication [Y/n] y
Change the root password? [Y/n] y
Remove anonymous users? [Y/n] y
Disallow root login remotely? [Y/n] y
Remove test database and access to it? [Y/n] y
Reload privilege tables now? [Y/n] y Pour l'importation de la base de donnée, cela sera via le compte root. Avec un autre compte même avec les mêmes priviligère que root, ça ne fonctionne pas.
Installation d’Apache et PHP
apt -y install \
apache2 \
libapache2-mod-php \
php \
php-apcu \
php-cas \
php-cli \
php-curl \
php-gd \
php-gmp \
php-imap \
php-intl \
php-json \
php-ldap \
php-mysql \
php-mbstring \
php-xml \
php-xmlrpc \
php-zip
Sauvegarde de l'ancien GLPI
Backup de la base de donnée
Soit on sauvegarde seulement la base de GLPI ou la totalité, surtout si on a un OCS Inventory
mysqldump -u root -p glpi > dump-glpi-2020-06-22.sql
mysqldump -all-databases > dump-all_base.sql
tar -zcvf dump.sql Backup binaire
tar -zcvf glpi-backup.tar.gz /var/www/glpi Pas indispensable, juste une sécurité.
Lister les plugins utilisé
Transfert des backups vers le nouveau serveur
scp glpi-backup.tar.gz root@xxxxxxxxx:/var/www/
scp dump-glpi-2020-06-22.sql root@xxxxxxxxx:/root/ Restauration des données de la base MySQL
Restauration
mysql -u root -p glpi_db < dump-glpi-2020-06-22.sql Contrôle de l'import du dump sql
mysql -u root -p
MariaDB [(none)]> USE glpi_db;
MariaDB [glpi_db]> SELECT DATABASE();
SHOW TABLES;
Installation de GLPI
Récupération des binaires
Récupérer GLPI sur le github officiel : https://github.com/glpi-project/glpi/releases
curl -OL https://github.com/glpi-project/glpi/releases/download/9.4.6/glpi-9.4.6.tgz
tar -xvf glpi-9.4.6.tgz -C /var/www/
chown -R www-data:www-data /var/www/glpi/ Apache
Création d’un certificat auto signé
mkdir -p /etc/ssl/localcerts
openssl req -new -x509 -days 365 -nodes -out /etc/ssl/localcerts/apache.pem -keyout /etc/ssl/localcerts/apache.key
chmod 600 /etc/ssl/localcerts/apache* Le GLPI n'est accessible que sur le réseau interne, le certificat auto signé est intégré dans l'AD.
Si le GLPI est accessible, utiliser Let's Encrypt
Création du vhost SSL
Editer le fichier /etc/apache2/sites-available/new.glpi.local.conf
<VirtualHost *:80>
#Redirection du flux TCP 80 vers TCP 443
ServerName glpi.local
ServerAlias *.glpi.local
RewriteEngine On
RewriteRule ^(.*)$ https://%{HTTP_HOST}$1 [R=301,L]
</VirtualHost>
<VirtualHost *:443>
ServerName glpi.local
ServerAlias *.glpi.local
ServerAdmin webmaster@localhost
DocumentRoot /var/www/glpi
<Directory /var/www/glpi>
Options -Indexes +FollowSymLinks
AllowOverride All
Require all granted
</Directory>
# Paramètres SSL
SSLEngine on
SSLCertificateFile /etc/ssl/localcerts/apache.pem
SSLCertificateKeyFile /etc/ssl/localcerts/apache.key
SSLProtocol all -SSLv2 -SSLv3
SSLHonorCipherOrder on
SSLCompression off
SSLOptions +StrictRequire
SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA$ Header always set Strict-Transport-Security "max-age=31536000; includeSubDomains"
# Log
LogLevel warn
ErrorLog ${APACHE_LOG_DIR}/*.glpi.local-error.log
CustomLog ${APACHE_LOG_DIR}/*.glpi.local-access.log combined
</VirtualHost> Mod à activer
a2enmod rewrite
a2enmod ssl Activer le vhost
a2ensite new.glpi.local.conf
a2dissite 000-default.conf Contrôle de la configuration
apache2ctl configtest Si ce message d’erreur apparaît :
Invalid command 'Header', perhaps misspelled or defined by a module not included in the server configuration
Action 'configtest' failed.
Exécuter la commande suivante
cp -arp /etc/apache2/mods-available/headers.load /etc/apache2/mods-enabled/headers.loadRelancer Apache
systemctl restart apache2 Installation & mise à jour

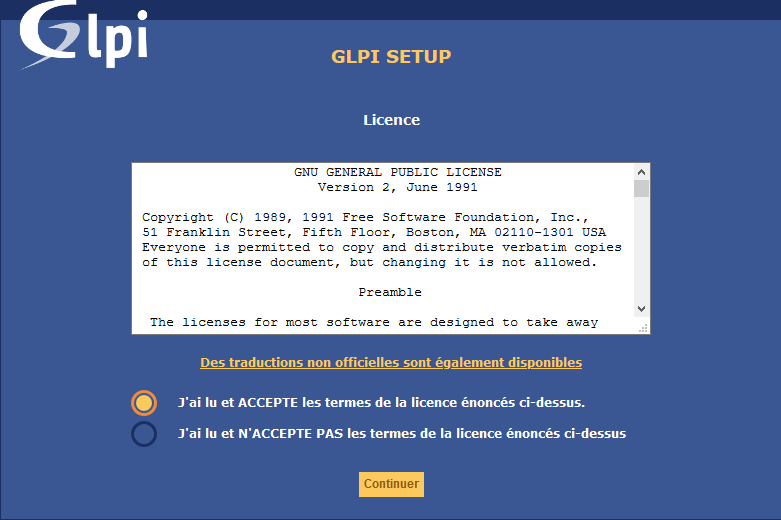



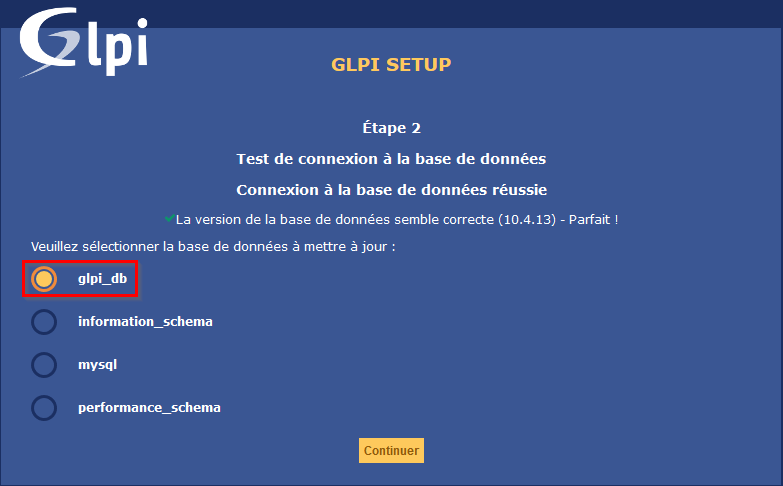


Migration de la DB en innodb

cd /var/www/glpi/
php bin/console glpi:migration:myisam_to_innodb
Installation automatisé de Debian 10
Prérequis
Il nous faut les deux paquets suivant :
- xorriso : extraction de l'iso
- genisoimage : création de l'iso personnalisé
apt update && apt -y install xorriso genisoimageDownload de l'image Debian
curl -LO# https://cdimage.debian.org/debian-cd/current/amd64/iso-cd/debian-10.8.0-amd64-netinst.isoExtraction de l'ISO
xorriso -osirrox on -indev debian-10.8.0-amd64-netinst.iso -extract / isofiles/Download du tamplate de pré configuration
curl -#L https://www.debian.org/releases/stable/example-preseed.txt -o preseed.cfgConfiguration du fichier de pré configuration
Les locales
#### Contents of the preconfiguration file (for buster)
### Localization
# Preseeding only locale sets language, country and locale.
d-i debian-installer/locale string en_US
# The values can also be preseeded individually for greater flexibility.
#d-i debian-installer/language string en
#d-i debian-installer/country string NL
#d-i debian-installer/locale string en_GB.UTF-8
# Optionally specify additional locales to be generated.
d-i localechooser/supported-locales multiselect en_US.UTF-8, fr_FR.UTF-8
# Keyboard selection.
d-i keyboard-configuration/xkb-keymap select fr(latin9)
# d-i keyboard-configuration/toggle select No togglingLe réseau
Dans mon cas, je laisse en mode DHCP pour IPv4 et IPv6 et le système va choisir de lui même son interface IP.
Il est possible d'attribuer des IP fixes.
### Network configuration
# Disable network configuration entirely. This is useful for cdrom
# installations on non-networked devices where the network questions,
# warning and long timeouts are a nuisance.
#d-i netcfg/enable boolean false
# netcfg will choose an interface that has link if possible. This makes it
# skip displaying a list if there is more than one interface.
d-i netcfg/choose_interface select auto
# To pick a particular interface instead:
#d-i netcfg/choose_interface select eth1
# To set a different link detection timeout (default is 3 seconds).
# Values are interpreted as seconds.
#d-i netcfg/link_wait_timeout string 10
# If you have a slow dhcp server and the installer times out waiting for
# it, this might be useful.
#d-i netcfg/dhcp_timeout string 60
#d-i netcfg/dhcpv6_timeout string 60
# If you prefer to configure the network manually, uncomment this line and
# the static network configuration below.
#d-i netcfg/disable_autoconfig boolean true
# If you want the preconfiguration file to work on systems both with and
# without a dhcp server, uncomment these lines and the static network
# configuration below.
#d-i netcfg/dhcp_failed note
#d-i netcfg/dhcp_options select Configure network manually
# Static network configuration.
#
# IPv4 example
#d-i netcfg/get_ipaddress string 192.168.1.42
#d-i netcfg/get_netmask string 255.255.255.0
#d-i netcfg/get_gateway string 192.168.1.1
#d-i netcfg/get_nameservers string 192.168.1.1
#d-i netcfg/confirm_static boolean true
#
# IPv6 example
#d-i netcfg/get_ipaddress string fc00::2
#d-i netcfg/get_netmask string ffff:ffff:ffff:ffff::
#d-i netcfg/get_gateway string fc00::1
#d-i netcfg/get_nameservers string fc00::1
#d-i netcfg/confirm_static boolean trueNom d'hôtes et de domaine
d-i netcfg/get_hostname string Nom de la machine
d-i netcfg/get_domain string Votre.Domaine
Si le réseau est configuré en IPv6, le nom de la machine sera son adresse IP, pour y remédier, il faut forcer le nom sur cette ligne
d-i netcfg/hostname string Nom de la machine
# Any hostname and domain names assigned from dhcp take precedence over
# values set here. However, setting the values still prevents the questions
# from being shown, even if values come from dhcp.
d-i netcfg/get_hostname string install
d-i netcfg/get_domain string lab.lan
# If you want to force a hostname, regardless of what either the DHCP
# server returns or what the reverse DNS entry for the IP is, uncomment
# and adjust the following line.
d-i netcfg/hostname string installWifi
# Disable that annoying WEP key dialog.
d-i netcfg/wireless_wep string
# The wacky dhcp hostname that some ISPs use as a password of sorts.
#d-i netcfg/dhcp_hostname string radishAjout automatique de firmware non libre
Décommenté la ligne si vous désirez que Debian ce débrouille a chercher des drivers non libre.
# If non-free firmware is needed for the network or other hardware, you can
# configure the installer to always try to load it, without prompting. Or
# change to false to disable asking.
#d-i hw-detect/load_firmware boolean trueConsole réseau
En ce qui me concerne cela n'a pas d'intérêt
### Network console
# Use the following settings if you wish to make use of the network-console
# component for remote installation over SSH. This only makes sense if you
# intend to perform the remainder of the installation manually.
#d-i anna/choose_modules string network-console
#d-i network-console/authorized_keys_url string http://10.0.0.1/openssh-key
#d-i network-console/password password r00tme
#d-i network-console/password-again password r00tmeConfiguration du miroir d'installation
Par défaut on est sur un serveur aux USA, j'ai configuré pour passer sur un miroir situé en France
### Mirror settings
# If you select ftp, the mirror/country string does not need to be set.
#d-i mirror/protocol string ftp
d-i mirror/country string manual
d-i mirror/http/hostname string ftp.fr.debian.org
d-i mirror/http/directory string /debian
d-i mirror/http/proxy string
# Suite to install.
#d-i mirror/suite string testing
# Suite to use for loading installer components (optional).
#d-i mirror/udeb/suite string testingConfiguration utilisateurs
Dans mon cas, je ne configure que le compte root avec le mot hacher en sha-512 via la commande :
mkpasswd -m sha-512
Le résultat de la commande remplacera le champ : [crypt(3) hash]
### Account setup
# Skip creation of a root account (normal user account will be able to
# use sudo).
#d-i passwd/root-login boolean false
# Alternatively, to skip creation of a normal user account.
d-i passwd/make-user boolean false
# Root password, either in clear text
#d-i passwd/root-password password r00tme
#d-i passwd/root-password-again password r00tme
# or encrypted using a crypt(3) hash.
d-i passwd/root-password-crypted password (crypt(3) hash)
# To create a normal user account.
#d-i passwd/user-fullname string Debian User
#d-i passwd/username string debian
# Normal user's password, either in clear text
#d-i passwd/user-password password insecure
#d-i passwd/user-password-again password insecure
# or encrypted using a crypt(3) hash.
#d-i passwd/user-password-crypted password [crypt(3) hash]
# Create the first user with the specified UID instead of the default.
#d-i passwd/user-uid string 1010
# The user account will be added to some standard initial groups. To
# override that, use this.
#d-i passwd/user-default-groups string audio cdrom videoTime zone
### Clock and time zone setup
# Controls whether or not the hardware clock is set to UTC.
# d-i clock-setup/utc boolean true
# You may set this to any valid setting for $TZ; see the contents of
# /usr/share/zoneinfo/ for valid values.
d-i time/zone string Europe/Paris
# Controls whether to use NTP to set the clock during the install
d-i clock-setup/ntp boolean true
# NTP server to use. The default is almost always fine here.
#d-i clock-setup/ntp-server string ntp.example.comPartitionnement
### Partitionnement
# On force le partitionnement sur le premier disque
d-i partman-auto/disk string /dev/sda
# Je veux un partitionement sans raid ni LVM.
# The presently available methods are:
# - regular: use the usual partition types for your architecture
# - lvm: use LVM to partition the disk
# - crypto: use LVM within an encrypted partition
d-i partman-auto/method string regular
# Supressions des avertissement si une partion LVM existe
d-i partman-lvm/device_remove_lvm boolean true
# Pareil mais pour le RAID
d-i partman-md/device_remove_md boolean true
# Iil en va de même pour la confirmation de l'écriture des partitions lvm.
d-i partman-lvm/confirm boolean true
d-i partman-lvm/confirm_nooverwrite boolean true
# On ne va créer que une seule partition
# - atomic: all files in one partition
# - home: separate /home partition
# - multi: separate /home, /var, and /tmp partitions
d-i partman-auto/choose_recipe select atomicTable en GPT
d-i partman-basicfilesystems/choose_label string gpt
d-i partman-basicfilesystems/default_label string gpt
d-i partman-partitioning/choose_label string gpt
d-i partman-partitioning/default_label string gpt
d-i partman/choose_label string gpt
d-i partman/default_label string gpt
partman-partitioning partman-partitioning/choose_label select gpt# Validation de la configuration du partitionnement.
d-i partman-partitioning/confirm_write_new_label boolean true
d-i partman/choose_partition select finish
d-i partman/confirm boolean true
d-i partman/confirm_nooverwrite boolean true
# Forcer l'utilisation des UUID que les noms de périphériques
d-i partman/mount_style select uuid
Post installation
Pour mes besoins je dois installer l'agent zabbix.
# script post install
d-i preseed/late_command string \
in-target wget https://repo.zabbix.com/zabbix/5.0/debian/pool/main/z/zabbix-release/zabbix-release_5.0-1+buster_all.deb; \
in-target dpkg -i zabbix-release_5.0-1+buster_all.deb; \
in-target apt update; \
in-target apt install -y zabbix-agentCréation de l'ISO personnalisé
Modification du boot loader
Cette modification permet de ne pas avoir le menu de sélection et de passer directement sur l'installation automatique
BIOS : isolinux
Modification du fichier isofiles/isolinux/isolinux.cfg en commentant ou enlevant la ligne default vesamenu.c32
UEFI : grub
Modification non faite, car je suis en vm
Ajout du fichier de pré configuration dans initrd
chmod +w -R isofiles/install.amd/
gunzip isofiles/install.amd/initrd.gz
echo preseed.cfg | cpio -H newc -o -A -F isofiles/install.amd/initrd gzip isofiles/install.amd/initrd
chmod -w -R isofiles/install.amd/Génération du checksum MD5
cd isofiles/
chmod a+w md5sum.txt
md5sum `find -follow -type f` > md5sum.txt
chmod a-w md5sum.txt
cd ..Création de l'ISO
chmod a+w isofiles/isolinux/isolinux.bin
genisoimage -r -J -b isolinux/isolinux.bin -c isolinux/boot.cat -no-emul-boot -boot-load-size 4 -boot-info-table -o debian-10-unattended.iso isofiles<iframe width="560" height="315" src="https://www.youtube.com/embed/7oC0d8cGBGQ" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
Mon fichier de configuration
### Localization
# Configurer la locale permet aussi de configurer
# la langue et le pays de l'OS
d-i debian-installer/locale string fr_FR.UTF-8
# Choix du clavier
# keymap est un alias de keyboard-configuration/xkb-keymap
d-i keymap select fr(latin9)
# On désactive la sélection fine de la configuration du clavier
#d-i keyboard-configuration/toggle select No toggling
### Configuration Réseau
# netcfg will choose an interface that has link if possible. This makes it
# skip displaying a list if there is more than one interface.
d-i netcfg/choose_interface select auto
# If you have a slow dhcp server and the installer times out waiting for
# it, this might be useful.
#d-i netcfg/dhcp_timeout string 60
#d-i netcfg/dhcpv6_timeout string 60
# Décomanté pour configurer manuellement le réseau
#d-i netcfg/disable_autoconfig boolean true
# If you want the preconfiguration file to work on systems both with and
# without a dhcp server, uncomment these lines and the static network
# configuration below.
#d-i netcfg/dhcp_failed note
#d-i netcfg/dhcp_options select Configure network manually
# Configuration statique du réseau.
#
# IPv4 example
#d-i netcfg/get_ipaddress string 192.168.1.42
#d-i netcfg/get_netmask string 255.255.255.0
#d-i netcfg/get_gateway string 192.168.1.1
#d-i netcfg/get_nameservers string 192.168.1.1
#d-i netcfg/confirm_static boolean true
#
# IPv6 example
#d-i netcfg/get_ipaddress string fc00::2
#d-i netcfg/get_netmask string ffff:ffff:ffff:ffff::
#d-i netcfg/get_gateway string fc00::1
#d-i netcfg/get_nameservers string fc00::1
#d-i netcfg/confirm_static boolean true
# Le nom d'hote et de domaine définit par le DHCP sont prioritaire.
d-i netcfg/get_hostname string install
d-i netcfg/get_domain string lab.lan
# Pour forcer le nom de l'hote
d-i netcfg/hostname string install
# Décommanter dans le cas d'utilisation de firware non reconnu automatiquent
#d-i hw-detect/load_firmware boolean true
### Configuration du mirroir d'instalation
# Décommanter la ligne suivante si mirroir en FTP
#d-i mirror/protocol string ftp
d-i mirror/country string manual
d-i mirror/http/hostname string ftp.fr.debian.org
d-i mirror/http/directory string /debian
d-i mirror/http/proxy string
### Configuration du compte root
# On saute la création d'un compte utilisateur normal.
d-i passwd/make-user boolean false
# Mot de passe root sera chiffré en achachage SHA-512
# Pour créer le hash utiliser la commande : mkpasswd -m sha-512
# Valeur optenue a indiquer à la place de [crypt(3) hash]
d-i passwd/root-password-crypted password [crypt(3) hash]
### Configuration de l'horloge et du fuseau horaire
# Contrôle si l'horloge matérielle est réglée sur UTC ou non..
#d-i clock-setup/utc boolean true
# Définition de la zone géographique.
d-i time/zone string Europe/Paris
# Contrôle l'utilisation du protocole NTP pour régler l'horloge pendant l'installation.
d-i clock-setup/ntp boolean true
# Serveur NTP à utiliser. La valeur par défaut convient presque toujours.
#d-i clock-setup/ntp-server string ntp.example.com
### Partitionnement
# On force le partitionnement sur le premier disque
d-i partman-auto/disk string /dev/sda
# Je veux un partitionement sans raid ni LVM.
# The presently available methods are:
# - regular: use the usual partition types for your architecture
# - lvm: use LVM to partition the disk
# - crypto: use LVM within an encrypted partition
d-i partman-auto/method string regular
# Supressions des avertissement si une partion LVM existe
d-i partman-lvm/device_remove_lvm boolean true
# Pareil mais pour le RAID
d-i partman-md/device_remove_md boolean true
# Iil en va de même pour la confirmation de l'écriture des partitions lvm.
d-i partman-lvm/confirm boolean true
d-i partman-lvm/confirm_nooverwrite boolean true
# On ne va créer que une seule partition
# - atomic: all files in one partition
# - home: separate /home partition
# - multi: separate /home, /var, and /tmp partitions
d-i partman-auto/choose_recipe select atomic
# Table de partition au format GPT
d-i partman-basicfilesystems/choose_label string gpt
d-i partman-basicfilesystems/default_label string gpt
d-i partman-partitioning/choose_label string gpt
d-i partman-partitioning/default_label string gpt
d-i partman/choose_label string gpt
d-i partman/default_label string gpt
partman-partitioning partman-partitioning/choose_label select gpt
# Validation de la configuration du partitionnement.
d-i partman-partitioning/confirm_write_new_label boolean true
d-i partman/choose_partition select finish
d-i partman/confirm boolean true
d-i partman/confirm_nooverwrite boolean true
# Forcer l'utilisation des UUID que les noms de périphériques
d-i partman/mount_style select uuid
### Base system installation
# Configure APT to not install recommended packages by default. Use of this
# option can result in an incomplete system and should only be used by very
# experienced users.
#d-i base-installer/install-recommends boolean false
# The kernel image (meta) package to be installed; "none" can be used if no
# kernel is to be installed.
#d-i base-installer/kernel/image string linux-image-686
d-i base-installer/kernel/image string linux-image-cloud-amd64
### Apt setup
# On pousse l'utilisation des dépots non-free & contrib.
d-i apt-setup/non-free boolean true
d-i apt-setup/contrib boolean true
# Uncomment this if you don't want to use a network mirror.
#d-i apt-setup/use_mirror boolean false
# Select which update services to use; define the mirrors to be used.
# Values shown below are the normal defaults.
#d-i apt-setup/services-select multiselect security, updates
#d-i apt-setup/security_host string security.debian.org
# Avoid CD/DVD scan
d-i apt-setup/cdrom/set-first boolean false
d-i apt-setup/cdrom/set-next boolean false
d-i apt-setup/cdrom/set-failed boolean false
### Package selection
#tasksel tasksel/first multiselect standard, web-server, kde-desktop
tasksel tasksel/first multiselect standard
# Instalation de packets suplémentaires
d-i pkgsel/include string openssh-server sudo curl git python3-pip unzip unattended-upgrades apt-listchanges
# Whether to upgrade packages after debootstrap.
# Allowed values: none, safe-upgrade, full-upgrade
#d-i pkgsel/upgrade select none
# Ne pas participer aux stats d'utilisation des packets.
popularity-contest popularity-contest/participate boolean false
### Boot loader installation
# Grub is the default boot loader (for x86). If you want lilo installed
# instead, uncomment this:
#d-i grub-installer/skip boolean true
# To also skip installing lilo, and install no bootloader, uncomment this
# too:
#d-i lilo-installer/skip boolean true
# This is fairly safe to set, it makes grub install automatically to the MBR
# if no other operating system is detected on the machine.
d-i grub-installer/only_debian boolean true
# This one makes grub-installer install to the MBR if it also finds some other
# OS, which is less safe as it might not be able to boot that other OS.
d-i grub-installer/with_other_os boolean true
# Due notably to potential USB sticks, the location of the MBR can not be
# determined safely in general, so this needs to be specified:
#d-i grub-installer/bootdev string /dev/sda
# To install to the first device (assuming it is not a USB stick):
d-i grub-installer/bootdev string default
# Alternatively, if you want to install to a location other than the mbr,
# uncomment and edit these lines:
#d-i grub-installer/only_debian boolean false
#d-i grub-installer/with_other_os boolean false
#d-i grub-installer/bootdev string (hd0,1)
# To install grub to multiple disks:
#d-i grub-installer/bootdev string (hd0,1) (hd1,1) (hd2,1)
# Optional password for grub, either in clear text
#d-i grub-installer/password password r00tme
#d-i grub-installer/password-again password r00tme
# or encrypted using an MD5 hash, see grub-md5-crypt(8).
#d-i grub-installer/password-crypted password [MD5 hash]
# Use the following option to add additional boot parameters for the
# installed system (if supported by the bootloader installer).
# Note: options passed to the installer will be added automatically.
#d-i debian-installer/add-kernel-opts string nousb
### Finishing up the installation
# During installations from serial console, the regular virtual consoles
# (VT1-VT6) are normally disabled in /etc/inittab. Uncomment the next
# line to prevent this.
#d-i finish-install/keep-consoles boolean true
# Avoid that last message about the install being complete.
d-i finish-install/reboot_in_progress note
# This will prevent the installer from ejecting the CD during the reboot,
# which is useful in some situations.
#d-i cdrom-detect/eject boolean false
# This is how to make the installer shutdown when finished, but not
# reboot into the installed system.
#d-i debian-installer/exit/halt boolean true
# This will power off the machine instead of just halting it.
#d-i debian-installer/exit/poweroff boolean true
### Preseeding other packages
# Depending on what software you choose to install, or if things go wrong
# during the installation process, it's possible that other questions may
# be asked. You can preseed those too, of course. To get a list of every
# possible question that could be asked during an install, do an
# installation, and then run these commands:
# debconf-get-selections --installer > file
# debconf-get-selections >> file
#### Advanced options
### Running custom commands during the installation
# d-i preseeding is inherently not secure. Nothing in the installer checks
# for attempts at buffer overflows or other exploits of the values of a
# preconfiguration file like this one. Only use preconfiguration files from
# trusted locations! To drive that home, and because it's generally useful,
# here's a way to run any shell command you'd like inside the installer,
# automatically.
# This first command is run as early as possible, just after
# preseeding is read.
#d-i preseed/early_command string anna-install some-udeb
# This command is run immediately before the partitioner starts. It may be
# useful to apply dynamic partitioner preseeding that depends on the state
# of the disks (which may not be visible when preseed/early_command runs).
#d-i partman/early_command \
# string debconf-set partman-auto/disk "$(list-devices disk | head -n1)"
# This command is run just before the install finishes, but when there is
# still a usable /target directory. You can chroot to /target and use it
# directly, or use the apt-install and in-target commands to easily install
# packages and run commands in the target system.
#d-i preseed/late_command string apt-install zsh; in-target chsh -s /bin/zsh
# script post install
d-i preseed/late_command string \
in-target wget https://repo.zabbix.com/zabbix/5.0/debian/pool/main/z/zabbix-release/zabbix-release_5.0-1+buster_all.deb; \
in-target dpkg -i zabbix-release_5.0-1+buster_all.deb; \
in-target rm -f zabbix-release_5.0-1+buster_all.deb; \
in-target apt update; \
in-target apt install -y zabbix-agentSources
https://wiki.debian.org/fr/DebianInstaller/Preseed
https://www.debian.org/releases/stable/amd64/apbs04.fr.html
https://wikitech.wikimedia.org/wiki/PartMan
Mise à jours automatique
Installation
apt install unattended-upgrades apt-listchangesLancement du service
systemctl enable unattended-upgrades
systemctl start unattended-upgradesConfiguration
/etc/apt/apt.conf.d/20auto-upgrades
APT::Periodic::Update-Package-Lists "1";
APT::Periodic::Unattended-Upgrade "1";
APT::Periodic::AutocleanInterval "7";
Test de fonctionnement
unattended-upgrades --dry-run --debug
Commandes de base
Des commandes de base sous GNU/Linux
Installation de Discord sur Debian 11
Pré-Requis
- Discord deb : https://dl.discordapp.net/apps/linux/0.0.16/discord-0.0.16.deb
- libappindicator1 : http://ftp.fr.debian.org/debian/pool/main/liba/libappindicator/libappindicator1_0.4.92-7_amd64.deb
- libdbusmenu-gtk4 : http://ftp.fr.debian.org/debian/pool/main/libd/libdbusmenu/libdbusmenu-gtk4_18.10.20180917~bzr492+repack1-2+b1_amd64.deb
- libindicator7 : http://ftp.fr.debian.org/debian/pool/main/libi/libindicator/libindicator7_0.5.0-4_amd64.deb
Méthode à suivre :
Installation des dépendances manquantes :
- sudo apt install libatomic1 libgconf-2-4 libc++1
- dpkg -i libdbusmenu-gtk4_18.10.20180917~bzr492+repack1-2+b1_amd64.deb
- dpkg -i libindicator7_0.5.0-4_amd64.deb
- dpkg -i libappindicator1_0.4.92-7_amd64.deb
- sudo dpkg -i discord-0.0.16.deb
Informations :
Discord dépend de :
- libatomic1 & libgconf-2-4 & libc++1 (installable via APT)
- libappindicator1 qui dépend de 2 modules :
-
- libdbusmenu-gtk4
- libindicator7
-
IMPORTANT : par soucis avec Wayland sur Debian avec Discord, si vous voulez stream vos écrans, passer sur X11 !
SSH - Ajout de la 2FA
La double authentification permet d'ajouter au système d'authentification classique (mot de passe ou clé SSH) une couche supplémentaire unique avec un code unique générer régulièrement.
Personnellement je l'utilise sur toutes les machines ou le SSH est activé sur le port publique.
Installation du module PAM Google Authenticator
! Ce produit est développé par Google mais aucune information personnelle ou donnée de tracking n'est envoyé à Google lors de son installation ou de son utilisation ! #RGPD
Le module s'installe de la manière la plus classique:
apt install libpam-google-authenticator -yConfiguration de PAM
Modifier le fichier /etc/pam.d/sshd pour ajouter:
auth required pam_google_authenticator.soConfiguration de sshd
Modifier le fichier /etc/ssh/sshd_config pour modifier la ligne:
ChallengeResponseAuthentication noPar:
ChallengeResponseAuthentication yesInitialisation de la 2FA
Il faut être connecté avec le compte sur lequel on souhaite activer la 2FA en ssh !
Lancer la commande suivante:
google-authenticatorEt répondre aux questions de la manière suivante:
Do you want authentication tokens to be time-based (y/n) y
# A ce moment le QR-Code apparait, pour évité qu'un écran petit cache le code après avoir répondu au question, il est recommander d'ajouter le code maintenant avec la "Ajout de la 2FA sur son mobile"
Do you want me to update your "/root/.google_authenticator" file? (y/n) y
# La réponse à la prochaine question dépant de vous
# Si vous réponder 'n' vous accepter qu'un code puisse être utiliser plusieurs fois
Do you want to disallow multiple uses of the same authentication
token? This restricts you to one login about every 30s, but it increases
your chances to notice or even prevent man-in-the-middle attacks (y/n) y
# La question suivante défini la possibilité d'utiliser un code dans les 4 minutes qui suive afin de compenser une de-synchronisation de temps
# Répondre 'y' autorise les 4 minutes mais augment les chances d'attaque
By default, a new token is generated every 30 seconds by the mobile app.
In order to compensate for possible time-skew between the client and the server,
we allow an extra token before and after the current time. This allows for a
time skew of up to 30 seconds between authentication server and client. If you
experience problems with poor time synchronization, you can increase the window
from its default size of 3 permitted codes (one previous code, the current
code, the next code) to 17 permitted codes (the 8 previous codes, the current
code, and the 8 next codes). This will permit for a time skew of up to 4 minutes
between client and server.
Do you want to do so? (y/n) n
# Ici on indique si oui ou non on veut limité le nombre d'essaie à la 2FA
# Très fortement déconseillier de mettre non car cela autoriserais un robot à faire une attaque brut-force
If the computer that you are logging into isn't hardened against brute-force
login attempts, you can enable rate-limiting for the authentication module.
By default, this limits attackers to no more than 3 login attempts every 30s.
Do you want to enable rate-limiting? (y/n) yRedémarrage du service sshd
Redémarrer le service sshd afin d'appliquer les paramètres:
systemctl restart sshdAjout de la 2FA sur son mobile
Il faut maintenant avoir un appareil (qui n'est pas celui sur lequel on à ajouter la 2FA) pour scanner le QR-code dans un générateur de 2FA.
Je recommande l'utilisation de Authy qui, synchroniser avec le nuage permet de retrouver sa 2FA sur un autre appareil en cas de perte du premier (ce qui n'est pas possible avec Google Authentification)
Vous pouvez aussi utiliser un gestionnaire de mot de passe qui prend en charge la 2FA (Bitwarden, ITGlue)
Voici comment faire pour ajouter un code sur Authy:
Lancer l'application connecté a votre compte (si vous en avez pas un, alors il faut le créer)
Choisir "Add Account"
L'application vous propose de scanner le QR ou d'entrer manuellement la clé.
Ensuite chercher "Terminal" pour que le logo soit celui du terminal et voilà la 2FA est sur votre téléphone.
Réseau
Firewall / Pare-feu
Installation d'un pare-feu
Installation de iptables
apt install iptablesCréation du process et des règles
Je créer un fichier firewall qui va être exécuter au démarrage et gérer par systemctl.
Son but et d'indiquer quoi faire quand on start le process et quand on le stop et la gestion du status.
nano /etc/init.d/firewall#! /bin/sh
### BEGIN INIT INFO
# Provides: Firewall
# Required-Start: $remote_fs $syslog
# Required-Stop: $remote_fs $syslog
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Firewall
# Description: Firewall
### END INIT INFO
IPT=/sbin/iptables
IP6T=/sbin/ip6tables
do_start() {
# Efface toutes les regles en cours. -F toutes. -X utilisateurs
$IPT -t filter -F
$IPT -t filter -X
$IPT -t nat -F
$IPT -t nat -X
$IPT -t mangle -F
$IPT -t mangle -X
$IP6T -t filter -F
$IP6T -t filter -X
$IP6T -t mangle -F
$IP6T -t mangle -X
# strategie (-P) par defaut : bloc tout l'entrant le forward et autorise le sortant
$IPT -t filter -P INPUT DROP
$IPT -t filter -P FORWARD DROP
$IPT -t filter -P OUTPUT ACCEPT
$IP6T -t filter -P INPUT DROP
$IP6T -t filter -P FORWARD DROP
$IP6T -t filter -P OUTPUT ACCEPT
# Loopback
$IPT -t filter -A INPUT -i lo -j ACCEPT
$IPT -t filter -A OUTPUT -o lo -j ACCEPT
$IP6T -t filter -A INPUT -i lo -j ACCEPT
$IP6T -t filter -A OUTPUT -o lo -j ACCEPT
# Permettre a une connexion ouverte de recevoir du trafic en entree
$IPT -t filter -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
$IP6T -t filter -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
echo "firewall started [OK]"
}
# fonction qui arrete le firewall
do_stop() {
# Efface toutes les regles
$IPT -t filter -F
$IPT -t filter -X
$IPT -t nat -F
$IPT -t nat -X
$IPT -t mangle -F
$IPT -t mangle -X
$IP6T -t filter -F
$IP6T -t filter -X
$IP6T -t mangle -F
$IP6T -t mangle -X
# remet la strategie
$IPT -t filter -P INPUT ACCEPT
$IPT -t filter -P OUTPUT ACCEPT
$IPT -t filter -P FORWARD ACCEPT
$IP6T -t filter -P INPUT ACCEPT
$IP6T -t filter -P OUTPUT ACCEPT
$IP6T -t filter -P FORWARD ACCEPT
#
echo "firewall stopped [OK]"
}
# fonction status firewall
do_status() {
# affiche les regles en cours
clear
echo Status IPV4
echo -----------------------------------------------
$IPT -L -n -v
echo
echo -----------------------------------------------
echo
echo status IPV6
echo -----------------------------------------------
$IP6T -L -n -v
echo
}
case "$1" in
start)
do_start
exit 0
;;
stop)
do_stop
exit 0
;;
restart)
do_stop
do_start
exit 0
;;
status)
do_status
exit 0
;;
*)
echo "Usage: /etc/init.d/firewall {start|stop|restart|status}"
exit 1
;;
esacNous avons ici la configuration la plus bloquante (trafic sortant uniquement): Uniquement le trafic local et les connexion établie vers l'extérieur en IPv4 et IPv6.
Pour ajouter des autorisation, par exemple l'ICMP (ping), dans do_start() ajouter:
# ICMP
$IPT -t filter -A INPUT -p icmp -j ACCEPT
$IP6T -t filter -A INPUT -p ipv6-icmp -j ACCEPTVotre do_start() ressemble à ça:
do_start() {
# Efface toutes les regles en cours. -F toutes. -X utilisateurs
$IPT -t filter -F
$IPT -t filter -X
$IPT -t nat -F
$IPT -t nat -X
$IPT -t mangle -F
$IPT -t mangle -X
$IP6T -t filter -F
$IP6T -t filter -X
$IP6T -t mangle -F
$IP6T -t mangle -X
# strategie (-P) par defaut : bloc tout l'entrant le forward et autorise le sortant
$IPT -t filter -P INPUT DROP
$IPT -t filter -P FORWARD DROP
$IPT -t filter -P OUTPUT ACCEPT
$IP6T -t filter -P INPUT DROP
$IP6T -t filter -P FORWARD DROP
$IP6T -t filter -P OUTPUT ACCEPT
# Loopback
$IPT -t filter -A INPUT -i lo -j ACCEPT
$IPT -t filter -A OUTPUT -o lo -j ACCEPT
$IP6T -t filter -A INPUT -i lo -j ACCEPT
$IP6T -t filter -A OUTPUT -o lo -j ACCEPT
# Permettre a une connexion ouverte de recevoir du trafic en entree
$IPT -t filter -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
$IP6T -t filter -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
# ICMP
$IPT -t filter -A INPUT -p icmp -j ACCEPT
$IP6T -t filter -A INPUT -p ipv6-icmp -j ACCEPT
echo "firewall started [OK]"
}Voici une liste de règles souvent utile
# ICMP
$IPT -t filter -A INPUT -p icmp -j ACCEPT
$IP6T -t filter -A INPUT -p ipv6-icmp -j ACCEPT
# DNS:53
$IPT -t filter -A INPUT -p tcp --dport 53 -j ACCEPT
$IPT -t filter -A INPUT -p udp --dport 53 -j ACCEPT
$IP6T -t filter -A INPUT -p tcp --dport 53 -j ACCEPT
$IP6T -t filter -A INPUT -p udp --dport 53 -j ACCEPT
#FTP:20+21 - FTP pasv: 10 090 - 10 100
$IPT -t filter -A INPUT -p tcp --dport 20 -j ACCEPT
$IP6T -t filter -A INPUT -p tcp --dport 20 -j ACCEPT
$IPT -t filter -A INPUT -p tcp --dport 21 -j ACCEPT
$IP6T -t filter -A INPUT -p tcp --dport 21 -j ACCEPT
$IPT -t filter -A INPUT -p tcp --dport 10090:10100 -j ACCEPT
$IP6T -t filter -A INPUT -p tcp --dport 10090:10100 -j ACCEPT
# SSH:22
# ATTENTION, indiques bien ton port personnalisé si tu l'as changé
$IPT -t filter -A INPUT -p tcp --dport 22 -j ACCEPT
$IP6T -t filter -A INPUT -p tcp --dport 22 -j ACCEPT
# HTTP:80 (Serveur Web)
$IPT -t filter -A INPUT -p tcp --dport 80 -j ACCEPT
$IP6T -t filter -A INPUT -p tcp --dport 80 -j ACCEPT
# HTTPS:443 (Serveur Web)
$IPT -t filter -A INPUT -p tcp --dport 443 -j ACCEPT
$IP6T -t filter -A INPUT -p tcp --dport 443 -j ACCEPT
# SNMP:161 (Monitoring)
$IPT -t filter -A INPUT -p udp --dport 161 -j ACCEPT
$IP6T -t filter -A INPUT -p udp --dport 161 -j ACCEPT
# SMTP:25 (Mail)
$IPT -t filter -A INPUT -p tcp --dport 25 -j ACCEPT
$IP6T -t filter -A INPUT -p tcp --dport 25 -j ACCEPT
# POP3:110 (Mail)
$IPT -t filter -A INPUT -p tcp --dport 110 -j ACCEPT
$IP6T -t filter -A INPUT -p tcp --dport 110 -j ACCEPT
# IMAP:143 (Mail)
$IPT -t filter -A INPUT -p tcp --dport 143 -j ACCEPT
$IP6T -t filter -A INPUT -p tcp --dport 143 -j ACCEPT Il faut maintenant rendre exécutable de fichier
chmod +x /etc/init.d/firewallLes prochaines étapes vont rendre actif le pare-feu. Si vous êtes en SSH et que une règle n'autorise pas le SSH vous risquer de vous auto bloqué a la prochaine connexion. Assurez-vous d'avoir un accès directe à la machine pour gérer le cas ou vous seriez dans l'incapacité de vous reconnecter.
Premier démarrage du pare-feu
/etc/init.d/firewall startGestion par systemctl
update-rc.d firewall defaults
systemctl enable firewall
systemctl start firewall
systemctl status firewallCela devrais vous indiquer quelque chose du genre:
● firewall.service - LSB: Firewall
Loaded: loaded (/etc/init.d/firewall; generated)
Active: active (exited) since *** ****-**-** **:**:** ****; * ago
Docs: man:systemd-sysv-generator(8)
Process: ***** ExecStart=/etc/init.d/firewall start (code=exited, status=0/SUCCESS)
***. ** **:**:** monitor systemd[1]: Starting LSB: Firewall...
***. ** **:**:** monitor firewall[30462]: firewall started [OK]
***. ** **:**:** monitor systemd[1]: Started LSB: Firewall.